The Tool That Isn’t There¶
The orchestration tools that exist were built for software engineering workflows, not research pipelines. Airflow, Prefect, n8n, LangChain, LlamaIndex: they optimize for deployment, scaling, and monitoring of production services. Research workflows have different requirements. Reproducibility over throughput. Provenance over performance. Human-in-the-loop review over full automation. Iterative design over one-shot deployment.
The tool that researchers actually need, one that coordinates LLM pipeline steps while maintaining research-grade provenance, supporting iterative design, and accounting for the unique failure modes of stochastic components, largely does not exist as a product. The market builds for software development, not for research documentation and statistical production. So practitioners build it, assemble it from parts, or adapt tools designed for different purposes.
This chapter does not recommend specific tools. Tools change too fast for recommendations to survive publication. Instead, it provides an evaluation framework, a set of dimensions for assessing any orchestration approach, and applies it to the current landscape. The framework will outlast the examples.
An Evaluation Framework for Orchestration¶
Four dimensions. Each applies to any tool, framework, or platform the reader evaluates, now or in five years.
Coupling. How tightly does the orchestration layer bind to specific models, providers, or frameworks? Can you swap a model without rewriting the orchestration logic? Can you change providers without restructuring the pipeline? Tight coupling means that changes to any single component propagate through the entire system. In a landscape where models change quarterly and providers update APIs without notice, coupling is a primary risk factor. The config-driven architecture from Chapter 7 is a direct countermeasure: if model identifiers, endpoints, and parameters live in configuration rather than in orchestration code, the coupling is loose by construction.
LangChain is the cautionary example. In the author’s experience, early versions tightly coupled pipeline logic to specific model APIs, chain abstractions, and internal conventions. When those conventions changed, which happened frequently, pipelines broke at the framework layer rather than the model layer. The abstraction that was supposed to insulate you from model changes became the thing that forced rewrites. Current versions have undergone significant migration and may have addressed some of these coupling patterns; the principle, not the specific product, is what matters. Coupling risk is not about whether a framework is good or bad. It is about how much of your pipeline you have to rewrite when any single dependency changes.
Friction. What is the operational overhead? Setup time, maintenance burden, debugging difficulty, learning curve, documentation quality. High-capability tools with high friction may cost more in researcher time than they save in automation. For the audience of this book, statisticians and data scientists who are not full-time software engineers, friction is often the binding constraint. A tool with 80% of the capability and 20% of the friction is usually the better choice.
Friction has two components: initial setup friction (getting the tool running at all) and ongoing maintenance friction (keeping it running as dependencies update, APIs change, and your pipeline evolves). Tools with low initial friction but high maintenance friction are traps. They feel easy at first and become expensive over time.
Transparency. Can you see what the orchestration layer is doing? Can you audit the sequence of operations it performed? Can you reproduce a run? For research workflows, transparency is not a nice-to-have. It is a provenance requirement. If the orchestration layer makes decisions (routing, retries, model selection, fallback handling) that you cannot inspect after the fact, you have a gap in your audit trail. Chapter 10’s provenance requirements apply to the orchestration layer itself, not just to the pipeline’s data processing.
Volatility. How likely is this tool, framework, or protocol to exist in its current form in two years? What is your migration cost if it does not? In the author’s assessment, the AI tool landscape’s effective shelf life is measured in months rather than years. Frameworks that were widely adopted eighteen months ago have in some cases been deprecated, substantially restructured, or lost their community momentum. Volatility assessment is not prediction. It is risk management. Prefer tools backed by active communities, open standards, or patterns that transfer across implementations. Avoid tools where the migration path, if the tool disappears, requires rewriting your entire pipeline.
Think about the tools in your current workflow. For each one, how would you rate it on these four dimensions? Which dimension is the biggest risk factor for your specific situation?
Categories of Orchestration¶
Managed platforms (n8n, Zapier, Make). Visual, low-code workflow builders. Low initial friction: you can build a working pipeline by connecting boxes and arrows. Coupling is high: your workflow logic lives inside the platform, and migrating to a different platform means rebuilding from scratch. Transparency varies: some provide execution logs, others are opaque. Volatility is moderate: these platforms have business models and user bases, but specific connectors and integrations change constantly. Best suited for simple, repeatable workflows where provenance requirements are minimal. For research pipelines with audit requirements, the transparency and coupling limitations are usually disqualifying.
Code-first frameworks (LangChain, LlamaIndex, Haystack, CrewAI, AutoGen). Powerful, flexible, rapid prototyping. Coupling risk is the primary concern: these frameworks often impose their own abstractions over model APIs, and when those abstractions change, which happens frequently in actively developed frameworks, your pipeline breaks at the framework layer. Friction is moderate to high: the learning curve is significant, and the APIs churn. Transparency depends on implementation: you can build transparent pipelines on these frameworks, but the framework itself may introduce opaque intermediary steps. Volatility is high: the code-first AI framework landscape is consolidating rapidly, and today’s leading framework may be tomorrow’s legacy code.
CLI-native and script-based. Python scripts, bash pipelines, Makefiles, task runners. Closest to how the audience already works. Maximum transparency: you wrote the code, you can read the code. Coupling is minimal: your pipeline logic is in your code, not in a framework’s abstractions. Friction is front-loaded: you build what you need rather than configuring what someone else built, so the initial investment is higher. But ongoing maintenance friction is lower because there are fewer intermediary layers to break. Volatility is low: Python and bash are not going anywhere. Best suited for teams that prioritize control, transparency, and long-term maintainability over rapid prototyping.
Custom and homegrown. Built for a specific domain, a specific workflow, a specific set of requirements that no existing tool satisfies. The system from Chapter 10 is an example: it exists because the eight provenance requirements were not satisfied by any available tool. High control, deep domain fit, high maintenance burden. The risk is overbuilding: creating infrastructure that costs more to maintain than the problem it solves. The mitigation: build the thinnest layer that satisfies your requirements, and build it on top of stable foundations (Python, SQLite, git) rather than on top of other frameworks.
| Dimension | Managed Platforms | Code-First Frameworks | CLI/Script-Based | Custom |
|---|---|---|---|---|
| Coupling | High (platform lock-in) | Moderate to high (framework abstractions) | Low (your code) | Low (your design) |
| Friction | Low initial, moderate ongoing | Moderate to high (API churn) | Higher initial, lower ongoing | Highest initial, variable ongoing |
| Transparency | Variable (often limited) | Variable (framework-dependent) | High (you wrote it) | High (you built it) |
| Volatility | Moderate | High (rapid landscape change) | Low (stable foundations) | Low (you control it) |
| Best for | Simple repeatable workflows | Rapid prototyping, complex chains | Research pipelines, audit needs | Domain-specific requirements |
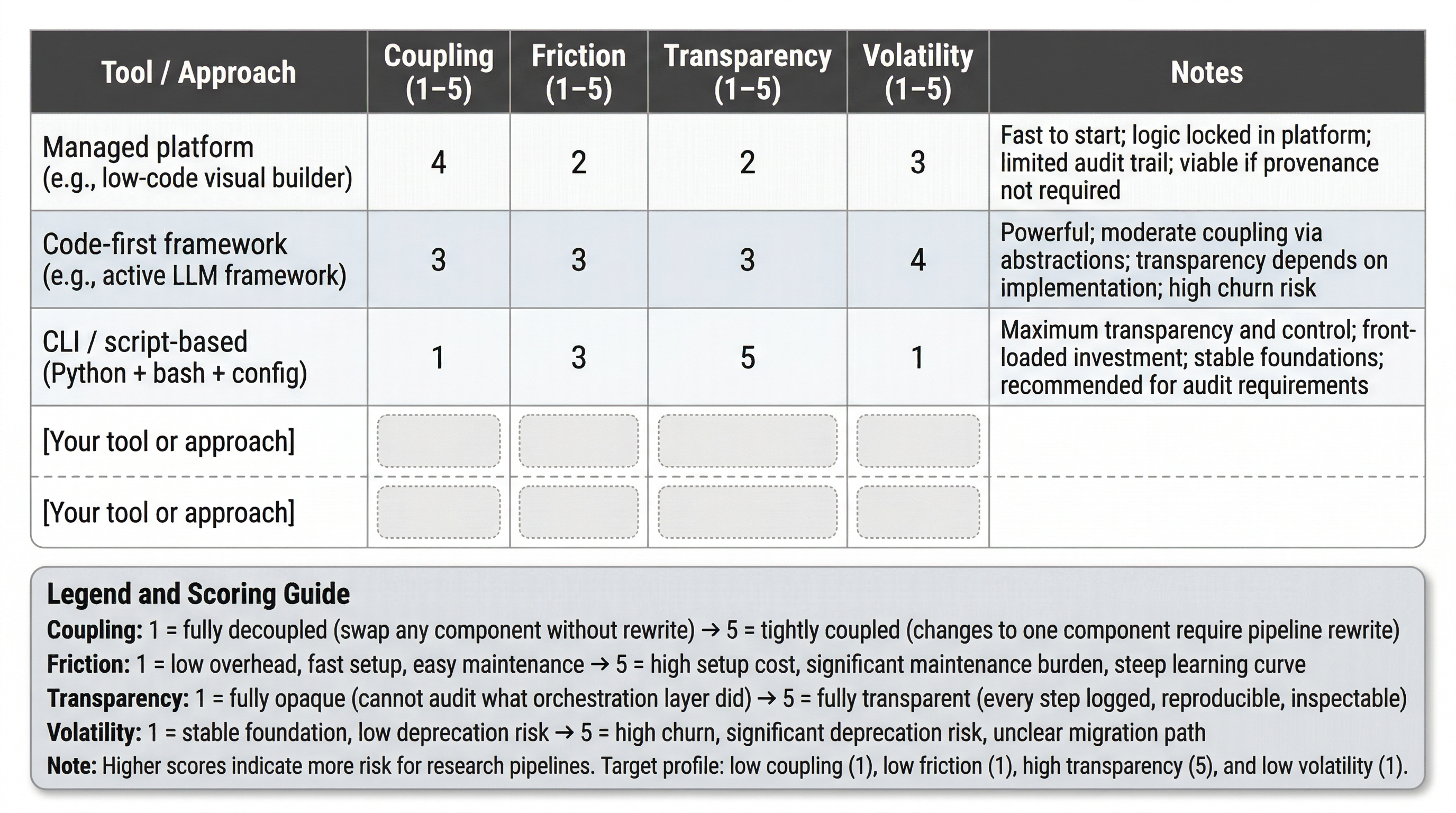
Figure 1:Orchestration evaluation framework template. Score any tool or approach on four dimensions (1–5 scale): Coupling (1 = fully decoupled, 5 = pipeline rewrite required), Friction (1 = low overhead, 5 = high setup cost), Transparency (1 = opaque, 5 = fully auditable), Volatility (1 = stable, 5 = high churn risk). Target profile for research pipelines: low coupling, low friction, high transparency, low volatility. The blank rows support direct evaluation of tools under consideration.
The 90/10 Rule and the Last Mile¶
The author has observed a consistent pattern across multiple tool adoption cycles. Call it the 90/10 rule: getting the first 90% of capability from any orchestration tool is straightforward. The last 10%, the edge cases, the error handling, the integration with your specific infrastructure, the compliance requirements your agency imposes, consumes 90% of the effort. Every demo works. Every tutorial succeeds. The question is what happens when the input data is malformed, the API returns an unexpected error, the model changes its output format, or the security review requires logging that the tool does not support.
The last mile problem is related but distinct. The last mile is the gap between “works in my development environment” and “works in production with my actual constraints.” For federal researchers, the last mile includes running inside authorized cloud environments with limited service catalogs, meeting data residency requirements that the tool was not designed for, satisfying audit requirements that the tool’s logging does not cover, and operating within network configurations that block services the tool assumes are available. Chapter 13 addresses the institutional dimension of this gap. Here, the point is architectural: evaluate tools based on last-mile fit, not demo capability.
The 90/10 rule and the last mile compound. A tool that gets you 90% of the way with 10% of the effort still leaves you with the hardest part: the last 10% of capability that happens to be the last mile of deployment. If that last 10% requires fighting the tool’s assumptions, you may spend more effort on the workaround than you would have spent building the capability yourself.
Think about a tool you adopted that worked beautifully in the demo but became painful in production. Where was the 90/10 boundary? What was the last-mile gap? Would you have made a different choice if you had evaluated it against the four dimensions first?
Tool Design for Observability¶
Agentic systems, where the AI partner builds, decides, and executes the workflow within guardrails you define, are a fundamentally different orchestration model than the categories above. Protocols like MCP (Model Context Protocol) do not orchestrate a predefined workflow. They define the boundaries within which an agent operates: what tools are available, what data they can access, what actions they can take. The agent decides the workflow at runtime.
This changes the observability problem. In a predefined pipeline, you instrument each step. In an agentic system, you do not know the steps in advance. Your only observability comes from what the tools themselves output. If your tools are designed to return only the final answer, you have no intermediate data, no decision trace, no evaluation signal. If your tools are designed to output structured data, confidence scores, provenance metadata, intermediate reasoning, disagreement flags, you have the monitoring and measurement data you need.
The Pragmatics system Webb, 2026 illustrates this principle. The MCP tools were designed to output the data needed for pipeline evaluation as a first-class concern, not as logging bolted on after the fact. Relevance scores, source metadata, expert judgment provenance, pipeline fidelity metrics: all returned as structured tool output, available for monitoring, evaluation, and audit. In agentic systems, tool design is your instrumentation strategy. If you do not design your tools to output measurement data, you will not get measurement data. No amount of orchestration-layer monitoring compensates for tools that return opaque results. This connects directly to Chapter 8 (evaluation by design) and Chapter 10 (provenance): the evaluation and provenance infrastructure must be designed into the tools themselves.
The FCSM AI-Ready Data paper Hoppe et al., 2025 recognizes this gap from the data side, distinguishing “machine-readable” from “machine-understandable” and recommending structured experiments with metadata-enhanced APIs, including MCP as an integration protocol. The federal statistical community is aware of the protocol. Awareness, however, is not the same as usability. The gap between “this protocol exists” and “a researcher can productively use it” is the friction dimension from the evaluation framework, applied to a specific case.
Context Windows, Working Memory, and the State Problem¶
Context windows are working memory, not long-term memory. Every orchestration approach must reckon with this constraint. A 200,000-token context window sounds large until you load a system prompt, a project configuration, a set of tool definitions, a conversation history, and the current task specification. What remains for the actual work, the data to process, the reasoning to perform, the intermediate results to hold, is a fraction of the total window.
The design implications are concrete. Treat the context window as a scarce resource to be managed, not a limitless workspace. Budget context the way you budget API costs: know what you are spending it on, and cut what does not earn its place. Plan for what happens when context fills up, when it gets compacted, when architectural decisions from earlier in the session get dropped. Compaction is lossy: the system decides what to keep and what to discard, and it does not always decide well. Critical state that lives only in the context window is state that can be silently dropped.
Externalize durable state. Chapter 7’s config-driven architecture is a direct countermeasure: if critical operating parameters live in configuration files rather than in the conversation, context loss does not destroy the pipeline’s operating state. Chapter 10’s state serialization (handoff documents) is another: capture the working context explicitly so it can be restored rather than relying on the context window to preserve it. Current approaches to extending effective context, retrieval-augmented generation, tool-use for external memory, context compression, all involve tradeoffs. RAG introduces retrieval variance (the stochastic tax from Chapter 1). Compression is lossy. External memory requires its own query and retrieval layer. There is no free lunch. The design principle: know which state must survive a context reset, externalize that state explicitly, and design the orchestration to restore it.
In your last long working session with an AI assistant, at what point did the conversation start losing track of earlier decisions? What would have been different if you had externalized the critical state at the beginning of the session rather than relying on the context window to hold it?
Recursive Stochasticity: The Full Treatment¶
Chapter 7 introduced the problem: you are designing systems to manage LLM stochasticity using tools that are themselves stochastic. This section delivers the full treatment.
The development toolchain, AI coding assistants, AI-assisted design conversations, AI-generated documentation, is part of the workflow architecture, whether you account for it or not. When the tool you use to build the pipeline introduces its own variability, your development process is a source of pipeline variance that compounds with runtime variance. The AI coding assistant ignores your configuration files and hardcodes values from its training data. It reinvents debugged infrastructure from scratch, introducing bugs you already fixed. Its knowledge is frozen at its training cutoff: it suggests deprecated models, uses outdated API signatures, proposes patterns that no longer work. Each new session starts fresh; architectural decisions from previous sessions are lost unless explicitly serialized.
Chen et al. (2026) measured this empirically. In a study of AI coding agents on long-term codebase maintenance, 100 tasks, each spanning an average of 233 days and 71 consecutive commits in real Python repositories, 75% of the models tested (18 models from 8 providers) broke previously working features during maintenance. The agents produce acceptable results on early iterations but create mounting technical debt as changes accumulate. The EvoScore metric, which weights later iterations more heavily, exposes the pattern: initial pass rates look acceptable, but accumulated regressions degrade the codebase over time.
Lee et al. (2026) provides empirical grounding for a related point: the harness, the code that constructs prompts, manages state, and determines what the model sees at each step, is not infrastructure plumbing but an optimization target. Harness optimization improved accuracy on 200 IMO-level problems by 4.7 points on average across five models not seen during the harness search; on text classification, a discovered harness improved accuracy by 7.7 points while using four times fewer context tokens. The cross-model generalization is the key finding: harness effects are systematic and transferable, not idiosyncratic noise. The design discipline this book advocates, config-driven architecture, specification before execution, provenance tracking, applies to the harness layer for the same reason it applies to the pipeline: systematic variation in what the model sees produces systematic variation in what the model outputs.
Your workflow architecture must account for the development process as a source of variability, not just the runtime pipeline. The same quality controls apply to both layers. Specification before execution (Chapter 10’s configuration control) means the AI coding assistant works from a written spec, not from its own interpretation of the task. Verification before commit catches regressions before they reach the repository. Regression testing detects when a “fix” breaks something that was previously working. State serialization between sessions preserves architectural decisions that would otherwise be lost to context resets.
The book’s thesis applies recursively: the design discipline required to build reliable LLM data pipelines is the same discipline required to work with LLM development tools. The infrastructure chapters, config-driven architecture (Chapter 7), evaluation by design (Chapter 8), state management (Chapter 10), are not just for your production pipeline. They are for your development workflow. The separation is artificial.
What to Bet On vs. What to Wait On¶
Bet on patterns, not products. Config-driven architecture, specification-before-execution, automated verification, graph-based provenance, deterministic retrieval where possible, regression testing, state serialization between sessions. These patterns are stable because they address fundamental problems, reproducibility, auditability, reliability, that do not depend on which specific tools implement them. The tools will change. The patterns will not. Every hour invested in a pattern pays dividends across tool transitions. Every hour invested in a tool-specific feature is at risk.
Wait on consolidation. The specific orchestration frameworks, agent platforms, and memory management solutions are consolidating but not yet settled. The framework that dominates in two years may not exist today. Use current tools if they help, framework-specific knowledge has immediate productivity value, but do not couple your pipeline’s core logic to them. Keep the coupling loose. If you can swap the orchestration layer without rewriting your data processing logic, your config management, or your evaluation infrastructure, then framework churn is a nuisance, not a crisis.
Build the thin adaptation layers. Config loaders, checkpoint managers, provenance hooks, verification gates, evaluation harnesses. These are the components that sit between your pipeline logic and whatever orchestration approach you use. They are your durable investment: small, well-tested modules that survive framework transitions because they depend on stable foundations (Python standard library, file I/O, SQLite, git) rather than on framework abstractions. When the orchestration layer changes, you rewrite the adapter, not the pipeline.
A Note on Industry Vocabulary¶
The AI engineering community is independently arriving at many of the same design patterns this book codifies, often under different names. This creates a translation problem for readers who encounter industry materials alongside the book: the concepts are the same, but the vocabulary diverges. The mapping below is one-directional. If you encounter these terms in industry materials, the corresponding book concept is what the term is pointing at. The book’s terminology is authoritative; the table helps you translate, not the reverse.
| If you encounter this term | The book’s concept | Chapter | Where the divergence is instructive |
|---|---|---|---|
| Skills / tool contracts / agent contracts | Model abstraction layer | Ch 6 | Industry frames as composability for multi-agent systems. Book frames as swap-readiness for model turnover. Same interface discipline, different motivation. |
| Second-look pattern / cross-verification agent | Ensemble / multi-model cross-validation | Ch 5 | Industry arriving at mandatory cross-verification from a capability argument. Book arrives from measurement theory (inter-rater reliability). Convergent evidence from different premises. |
| Deterministic hardwiring / trust tiers | Deterministic retrieval | Ch 9 | Industry sorts by risk level. Book sorts by fidelity requirement. Identical insight: some lookups must be exact. |
| Decoupled workflow state / crash-resilient DAG | Checkpoint and state serialization | Ch 7, Ch 10 | Industry frames as infrastructure resilience. Book frames as validity preservation (SFV T5). The SFV framing explains why state continuity matters, not just that it does. |
| Typed streaming events / structured event emission | Provenance chain / event log | Ch 10 | Industry wants machine-readable audit trails. Book wants defensible provenance. Same output, different name and different motivation. |
Look at your current pipeline architecture. What fraction of your code is pipeline logic versus orchestration glue? If you had to migrate to a different orchestration approach next quarter, how much of your code survives?
Thought Experiment¶
You designed a survey processing pipeline eighteen months ago using Framework X for orchestration. Framework X provided model chaining, retry logic, output parsing, and a visual dashboard for monitoring. Your pipeline processes 50,000 records quarterly for an official statistical release. It is embedded in a production workflow with downstream dependencies: other teams consume your output.
Framework X just announced end-of-life. The maintainers are moving to Framework Y, which has a different API, different abstractions, and no backward compatibility. Your next quarterly run is in six weeks.
How much of your pipeline can you salvage? Walk through the components: your data processing logic, your model invocation code, your evaluation infrastructure, your config management, your checkpoint and recovery logic, your provenance tracking. Which components are Framework X-specific and must be rewritten? Which components are pipeline logic that happens to run inside Framework X and can be extracted?
What would you design differently next time?
The orchestration layer coordinates your pipeline components, manages failures, and, if designed well, provides observability into the pipeline’s behavior. But every component in that orchestrated pipeline, every model, every framework, every protocol, every library, is a dependency with its own supply chain, its own update cycle, and its own security surface area.
The pipeline does not just need to work reliably. It needs to be secure. Models have provenance: where were they trained, on what data, by whom? Frameworks have dependencies: what packages do they pull in, and who maintains them? APIs have attack surfaces: what data crosses the network, and who can observe it? Chapter 12 addresses the security and supply chain implications of the architectures this book has been building.
- Webb, B. (2026). Pragmatics: Delivering Expert Judgment to AI Systems. Zenodo. 10.5281/zenodo.18913092
- Hoppe, T., Gonzalez, J., Mirel, L., & Schmitt, R. (2025). AI-Ready Federal Statistical Data: An Extension of Communicating Data Quality (Techreport FCSM 25-03). Federal Committee on Statistical Methodology.
- Chen, J., Xu, X., Wei, H., Chen, C., & Zhao, B. (2026). SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration. arXiv Preprint arXiv:2603.03823. https://arxiv.org/abs/2603.03823
- Lee, Y., Nair, R., Zhang, Q., Khattab, O., Lee, K., & Finn, C. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses. arXiv Preprint arXiv:2603.28052. https://arxiv.org/abs/2603.28052