The Silence of a Single Model¶
When a single model processes 10,000 records and returns 10,000 answers, the output looks clean. There are no disagreements, no flags, no ambiguity markers. Every record has a label. The pipeline ran without errors. The results look professional.
But silence is not the same as accuracy. The single-model pipeline does not surface what it does not know. It buries uncertainty in confident-sounding output. A wrong classification and a right classification look identical in the output file. There is nothing to disagree with, because there is only one opinion.
The first time you add a second model, you discover how much uncertainty was hidden. The Federal Survey Concept Mapper Webb, 2026 found that dual-model disagreement surfaced genuine ambiguity in survey question semantics: cases where the “right” classification was legitimately debatable, where the question genuinely spanned two domains, where the taxonomy itself was the problem. That disagreement was not a bug. It was the most valuable output of the pipeline.
This chapter provides the design patterns for three fundamentally different multi-model topologies, plus a framework for choosing between them. The thesis is simple: multi-model is the baseline, not the advanced technique. Single-model is what needs justification. If you cannot explain why a single model is sufficient for your task, you have not thought carefully enough about your uncertainty.
Topology 1: Parallel Consensus¶
Chapter 2 presented this pattern in detail through the Concept Mapper case study. This section abstracts the design elements that generalize across any classification, coding, or categorization task.
The pattern. N models receive the same input independently. Outputs are compared. Agreement indicates confidence; disagreement triggers escalation or adjudication.
Model selection for diversity of failure modes. The goal is not N copies of the same bias. It is N independently trained systems with different architectural assumptions. Models sharing training corpora (Common Crawl, Wikipedia, public web) are not statistically independent. But different architectures, training objectives, RLHF tuning, and parameter configurations produce different agreement patterns and failure behavior: models from different vendor families show lower exact agreement than models within the same family, which is precisely the diversity that makes cross-model validation informative.
The foundational principle behind parallel consensus is self-consistency: sampling multiple independent reasoning paths and selecting the most consistent answer Wang et al., 2022. The multi-model variant extends this from sampling within a single model to sampling across models with different training, which provides stronger independence guarantees, though cross-vendor models remain substantially correlated on hard cases Song & others, 2025.
Quantitative agreement definition. “Agreement” must be defined for the domain. Token match? Semantic similarity? Structured output field comparison? The Concept Mapper used structured output comparison against a fixed schema: the agreement metric was whether two models mapped a survey question to the same harmonized variable, a concept grounded in existing cross-study harmonization frameworks Fortier et al., 2011Wolf et al., 2016. Your agreement metric should be equally concrete.
Decision logic: N outputs to one decision. Majority vote? Confidence-weighted arbitration? Human-in-the-loop above a disagreement threshold? The decision rule must be explicit, versioned, and auditable. It is part of the pipeline configuration, not an informal convention.
Inter-rater reliability as the native evaluation framework. LLMs as independently trained neural networks are directly amenable to inter-rater reliability methods: Cohen’s kappa (two raters), Fleiss’ kappa (multiple raters, categorical data), Krippendorff’s alpha (flexible across scale types and rater counts). This is a transfer of existing statistical methodology, not a novel invention Webb, 2026. The multi-model pattern this chapter describes as a measurement design principle is independently emerging in AI engineering as a safety requirement for high-capability models. The motivation differs; the architecture is identical.
ABBA design for position bias control. Run Model A then Model B on the same input, then Model B then Model A. If results change based on order, you have detected position bias in your evaluation, not a real difference in model capability. This is standard counterbalancing from experimental design, applied to LLM evaluation.
Two-versus-three models is not the point. The point is: more than one look, stored comparisons, and a decision rule for disagreements. The optimal blend shifts as models update, which is why selection logic must be versioned and revisitable (Chapter 9 treats this as a formal drift concern).
If full parallel consensus is too expensive, run the second model on a stratified sample of outputs: the lowest-confidence results from the first model, plus a random sample of high-confidence results for calibration. Even partial cross-validation is better than none. The goal is not perfection; it is making hidden uncertainty visible on the cases most likely to be wrong.
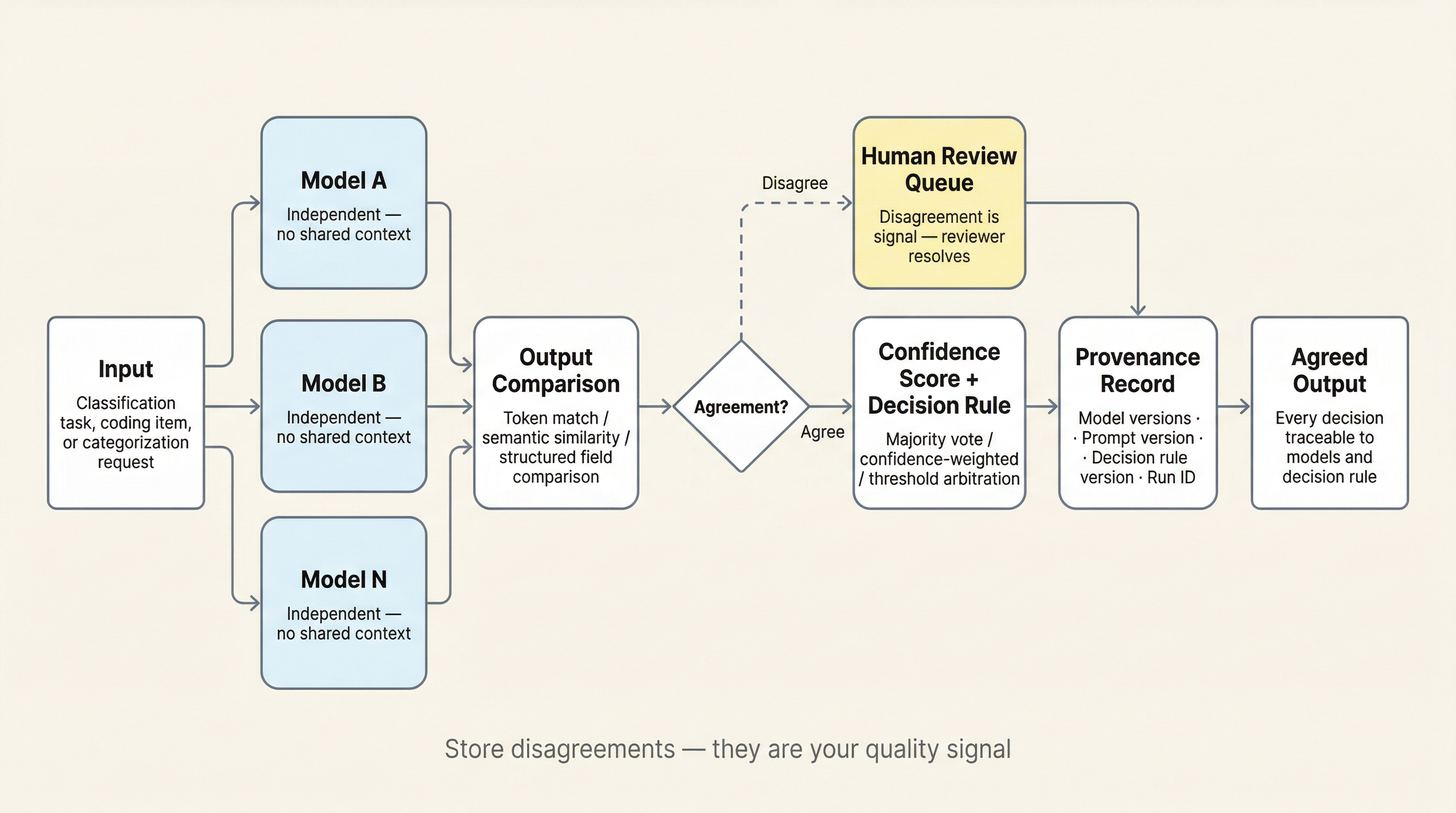
Figure 1:Parallel consensus topology. Input fans out to N independently prompted models. Agreed outputs proceed through the decision rule with a versioned provenance record. Disagreements route to human review and rejoin the flow. The disagreement rate is your primary quality signal.
You are designing a classification pipeline and your two models agree on 97% of cases. Is that 3% disagreement rate a sign of success or failure? What would you need to know to decide?
Topology 2: Generator-Critic Loops¶
This is a fundamentally different shape from parallel consensus. In consensus, models perform the same task independently. In a generator-critic loop, models perform different tasks in sequence: one generates, another evaluates, and the evaluation feeds back to improve the generation.
The canonical pattern. Madaan et al. (2023) introduced the Self-Refine framework: a single LLM generates an initial output, then provides feedback on its own output, then uses that feedback to refine iteratively. Across seven diverse tasks, Self-Refine improved performance by approximately 20% on average over single-shot generation, though gains varied substantially across tasks.
The critical limitation: same-model self-refinement degrades. This is where the chapter connects to Chapter 1’s iterative refinement trap. Chapter 1 documented five degradation pathways in self-refinement loops in detail. The core finding: LLMs cannot reliably self-correct their own reasoning without external feedback (Huang et al., 2024), and the failure modes compound: bias amplification, reward hacking, and theoretical limits on self-correction all work against you (Xu & others, 2024Pan & others, 2024Yang et al., 2025Lee & others, 2025).
The design implication for statistical production: same-model self-refinement is a trap. The model’s blind spots are systematic. Asking it to critique its own output does not surface errors it cannot see. The signal degrades rather than improves over successive iterations.
The cross-model variant. The more robust design separates the generator from the critic:
Model A generates structured output (extracts fields from administrative records into a target schema). Model B evaluates the output against schema constraints: not just “is this valid JSON” but “does this field value make semantic sense given the other fields?” Feedback loop: Model B rejects with specific reasons, and Model A (or Model C) gets another pass with the rejection rationale appended to the prompt. Termination conditions: maximum iterations (hard cap), critic passes all checks, confidence threshold met, or escalation to human review.
Design questions unique to this topology:
How many iterations before you bail? The degradation literature shows performance often flattens or degrades over multiple self-refinement turns, with no universal optimum. Design your termination condition around observed trajectory: if iteration N+1 is not measurably better than iteration N, stop. Monitor for oscillation (iteration 3 worse than iteration 2) as a signal to terminate immediately.
Does quality actually improve on retry, or does it oscillate? Monitor the trajectory. If iteration 3 is worse than iteration 2, you have oscillation, not convergence. Stop.
What is the prompt architecture for feeding rejection reasons back? The rejection must be specific and actionable, not “try again.” Vague feedback produces vague revisions.
When does the critic become the bottleneck? If the critic model is slower or more expensive than the generator, your loop economics invert. Cost the full cycle, not just the generation step.
When this topology earns its place. Complex extraction or generation tasks where the output must conform to a formal schema. Tasks where partial correctness is common: the model gets 8 of 10 fields right, but the remaining 2 need targeted revision. Tasks where the cost of a human review pass exceeds the cost of an automated critique cycle.
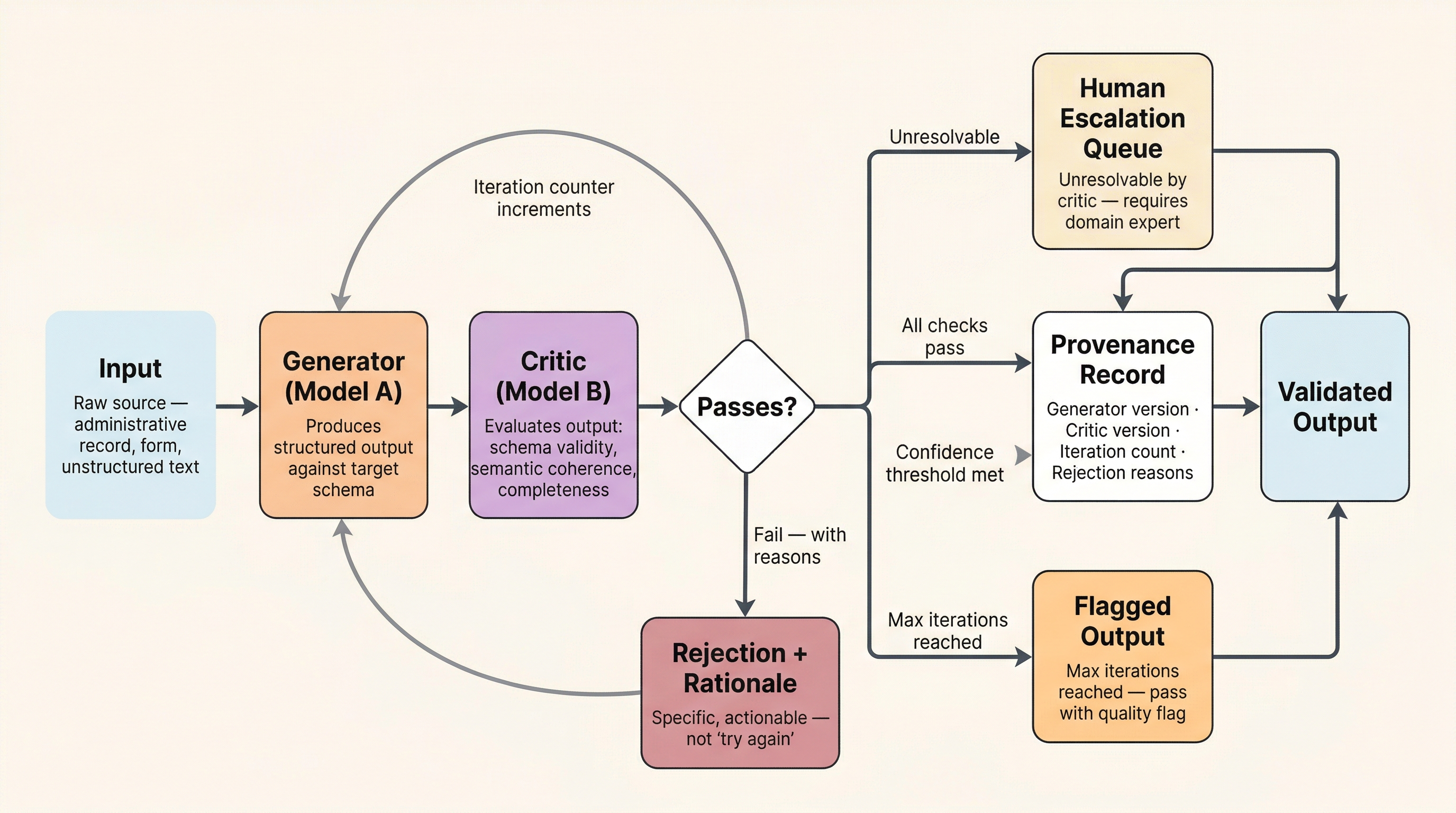
Figure 2:Generator-critic loop topology. Model A generates; Model B evaluates. Failed outputs return to the generator with specific rejection reasons. Four conditions terminate the loop: all checks pass, confidence threshold met, maximum iterations reached, or escalation to human review. All paths carry provenance of the iteration trajectory.
You design a generator-critic loop and notice that the critic approves 95% of outputs on the first pass. Is the critic too lenient, or is the generator that good? How would you calibrate?
Topology 3: LLM-as-Judge¶
The judge pattern is architecturally distinct from both consensus and refinement. It is delegation: a model explicitly tasked with meta-evaluation of another model’s output against defined criteria.
The research landscape. Gu et al. (2024) provide a comprehensive survey of LLM-as-a-Judge systems, addressing how to build reliable LLM evaluators. Li & others (2024) offer a complementary survey structured around functionality, methodology, and applications of LLM-based evaluation. Both surveys identify core challenges: consistency, bias mitigation, and rubric design.
Preference leakage. Li et al. (2024) exposed a contamination problem: when the judge model is related to the generator model, same model, same family, or fine-tuned from the same base, the judge exhibits systematic bias toward that model’s outputs. This directly reinforces the multi-model diversity argument. Your judge should not be your generator’s cousin.
Rubric design as the practitioner skill. Unlike consensus (where agreement is the metric) or critic loops (where schema conformance is the check), judge patterns require explicit evaluation criteria. The rubric defines what “good” means. For statistical production, rubrics should be:
Domain-grounded. Evaluation criteria drawn from existing quality frameworks: agency standards, style guides, subject-matter definitions.
Decomposed. Multi-trait evaluation outperforms holistic scoring. Break the judgment into separate dimensions: accuracy, completeness, format compliance, semantic coherence.
Versioned and auditable. The rubric is part of the pipeline configuration. When it changes, the change is tracked.
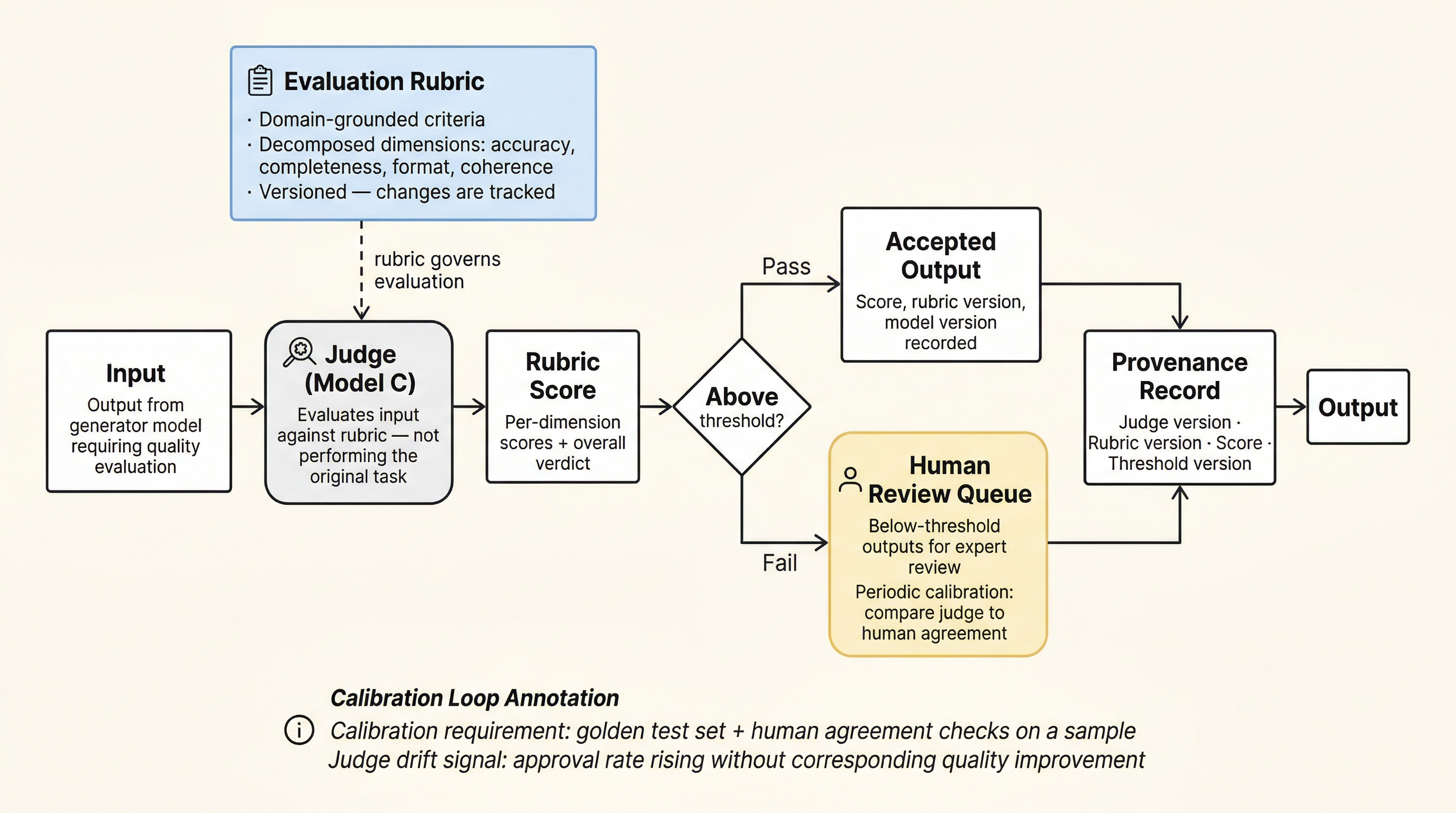
Figure 3:LLM-as-Judge topology. A dedicated judge model evaluates generator output against a versioned rubric. Outputs scoring above threshold are accepted with provenance; below-threshold outputs route to human review. Periodic calibration against a golden test set is a design requirement, not optional maintenance.
Judge pattern variants:
Tie-breaking arbiter. Models A and B disagree; Model C adjudicates. Different from consensus because C is evaluating A and B’s outputs, not performing the original task independently.
Quality gate. Every output passes through a judge before entering the production pipeline. The judge scores against the rubric; outputs below threshold are flagged for human review.
Pairwise comparison. The judge receives two candidate outputs and selects the better one against criteria. Useful for prompt optimization and model selection experiments.
Failure modes specific to this topology. The judge may lack domain knowledge: a general-purpose LLM evaluating domain-specific statistical output may not catch errors that a subject-matter expert would. Rubric gaming: models optimized against a rubric will find shortcuts that satisfy the letter but not the spirit of the criteria, a form of Goodhart’s Law (when a measure becomes a target, it ceases to be a good measure) applied to LLM evaluation. Who judges the judge? At some point, human calibration is required. Golden test sets, periodic human agreement checks, and rubric revision cycles are part of the operating cost. Position bias in pairwise comparison: the order in which candidates are presented affects the judge’s preference. ABBA counterbalancing applies here too.
You deploy an LLM judge to quality-check extraction outputs. After a month, you notice the approval rate has climbed from 82% to 96%. Is the generator improving, or has the judge drifted? What data would you need to tell the difference?
Choosing Your Topology¶
Not every problem needs a multi-model solution. Not every multi-model solution needs a complex topology. The decision depends on the task structure, the evaluation requirements, and the cost constraints.
When parallel consensus fits. Classification tasks with discrete output categories. Tasks where you have an existing evaluation framework (inter-rater reliability). High-volume batch processing where you can afford 2-3x the API cost. Cases where disagreement itself is the most valuable signal.
When generator-critic loops fit. Complex generation or extraction tasks with schema constraints. Tasks where partial correctness is the norm (most of the output is right, but specific fields need revision). Cases where the cost of a human review pass exceeds an automated critique cycle. When you need a provenance trail of why the output changed between iterations.
When LLM-as-Judge fits. Quality gating before production release. Model selection and prompt optimization experiments. Tasks requiring nuanced evaluation against multi-dimensional criteria. When you need a scalable alternative to human quality review.
When the answer is none of the above. Sometimes the smart design move is not throwing more models at the problem. Lin et al. (2025) demonstrate this with TWIX, a structured data extraction tool that infers the underlying visual template from templatized documents (invoices, police records, tax forms) and then extracts data based on that template: 520x faster and 3,786x cheaper than GPT-4 Vision, with higher accuracy. TWIX uses LLMs sparingly for semantic disambiguation, not as the primary extractor. The lesson: understand the structure of your problem before reaching for the model. If the documents share a template, exploit the template. If the classification has a fixed taxonomy, a lookup table handles the easy cases. Multi-model designs earn their place when the task genuinely requires judgment under ambiguity, not when a cheaper, more deterministic approach would suffice.
This connects directly to Chapter 2’s “try the cheap thing first” principle. The Concept Mapper only moved to LLMs after embedding-based matching failed. The LLM solution was the second approach, not the first.
Table 1:Topology comparison. Three multi-model topologies compared across task type, evaluation method, cost profile, primary failure mode, and use conditions. The right topology depends on task structure, cost constraints, and what signal you are optimizing for.
| Parallel Consensus | Generator-Critic Loop | LLM-as-Judge | |
|---|---|---|---|
| Task type | Classification, coding, categorization with discrete outputs | Complex generation or extraction against a formal schema | Quality gating, model selection, multi-dimensional evaluation |
| Output relationship | N models, same task, independent | Generator produces; critic evaluates (different tasks in sequence) | Judge evaluates a single output against defined criteria |
| Evaluation method | Inter-rater reliability (kappa, alpha) | Schema conformance + trajectory monitoring | Rubric scores per dimension |
| Cost profile | 2-3x inference cost per item | Variable: base cost × iterations; critic adds per-loop overhead | Base cost + judge inference; one pass unless human escalation |
| Primary failure mode | Correlated errors when models share training; low disagreement masks systematic bias | Oscillation (iteration N+1 worse than N); reward hacking if generator games critic | Rubric gaming; judge drift over time; preference leakage from related models |
| Use when | Disagreement is itself the signal; volume justifies 2-3x cost; inter-rater framework applies | Partial correctness is typical; schema conformance is testable; retry cost beats human review cost | Quality gate before production; scalable alternative to human review; prompt optimization experiments |
| Do not use when | Models are correlated on your specific domain; volume is too low to amortize cost | No observable trajectory signal; critic is more expensive than human review; task lacks schema | Domain knowledge exceeds judge capability; rubric cannot be defined precisely; no calibration process in place |
In practice, pipelines combine topologies. The thought experiment at the end of this chapter asks you to do exactly this: consensus for classification, a critic loop for extraction, a judge gate for quality. The key design question when composing topologies is the interface between stages. Each topology produces output that feeds the next. The consensus stage’s agreed classifications become input to the extraction stage. The extraction stage’s structured output becomes input to the quality judge. Define the data contract at each interface: what fields, what format, what metadata carries forward, before you build any individual stage.
When models disagree, the arbitration strategy matters as much as the topology. Three common approaches, each with different cost and quality profiles: Use confidence-weighted arbitration when both models produce calibrated confidence scores and the task has a clear correct answer (classification into a fixed taxonomy). Use a third-model tiebreaker when the disagreement is semantic rather than probabilistic, when the question is “which interpretation is right” rather than “which model is more confident.” Use human review when the disagreement rate is low enough to be tractable (under 5-10% of records), when the stakes of a wrong answer are high, or when the disagreements themselves are the research finding you need to examine. The Concept Mapper used human review for its ~3% disagreement cases because the disagreements revealed genuine taxonomic ambiguity that no automated rule could resolve Webb, 2026. The arbitration strategy is a design decision that belongs in your pipeline configuration alongside the topology choice, not an afterthought.
Cross-Cutting Design Principles¶
Regardless of topology, these principles apply:
Version everything. Model identifiers, prompt versions, rubric versions, confidence thresholds, decision rules. When any component changes, the change is tracked and the pipeline can be rerun with the prior configuration for comparison.
Define a minimum provenance record. Every pipeline output record should carry at minimum: a unique input record identifier, the model identifier and version used, the prompt template version, a timestamp, the raw output, the final classified/extracted value, a confidence or agreement flag, and the decision rule that produced the final value (majority vote, confidence-weighted, human override). For multi-model topologies, add each model’s individual output and the arbitration path taken. This is the minimum set that allows you to answer “why did this record get this result?” six months later. Chapter 10 provides the infrastructure for storing and querying these records at scale; this section defines what to capture.
Store the disagreements, not just the resolutions. The cases where models disagree are your most valuable data for understanding pipeline behavior. Discarding disagreement metadata is discarding your quality signal.
Design for model transience. Models are deprecated, updated, and replaced. Your pipeline must survive a model swap without architectural redesign. Golden test sets, model-agnostic interfaces, and version pinning with expiration dates are design requirements, not nice-to-haves Webb, 2026.
Cost the full cycle, not just the inference call. A multi-model pipeline’s cost includes API calls for all models, retry and refinement iterations, human review for escalated cases, and the engineering time to maintain the orchestration. The $15 per-run inference cost for the Concept Mapper was real; the human engineering cost dwarfed it. The throughput cost of a multi-model architecture is also real: a dual-model pipeline with arbitration requires roughly twice the API calls of a single-model pipeline. Chapter 6 covers The Throughput Ladder and the local-versus-API tradeoff that determines whether this overhead is acceptable at your scale.
Reprocessing advantage. Unlike manufacturing, reprocessing data costs electrons, not materials. If a model is updated or a rubric is revised, you can rerun the pipeline. Design around this advantage: store inputs, version everything, and build for reproducibility.
You have budget and engineering time for three of these five principles in your first release. Which three do you choose, and what risk does each omission create?
Thought Experiment¶
Your agency produces an annual statistical report that requires extracting structured data from 5,000 administrative records (PDF forms from state agencies), classifying each record into one of 12 program categories, and flagging records with potential data quality issues.
You have been asked to design an LLM-powered pipeline. Consider:
Which topology (or combination) would you use for the extraction step? For the classification step? For the quality flagging step? Are they the same?
The forms come from 50 states with slightly different layouts. Does this change your extraction approach? Do you need an LLM at all for the structured extraction, or would a template-based approach serve better?
Your budget allows for approximately $500 in API costs per annual run. How does this constrain your topology choices? What would you sacrifice first: the second model, the critic loop, or the judge gate?
The report is published once a year but the methodology must be defensible to Congress. How does this change your provenance and auditability requirements versus a pipeline that runs daily for internal use?
You now have three topologies for combining models and a framework for choosing between them. But knowing which pattern does not tell you how the pieces execute. When you run two models on 10,000 records, do they run in parallel or in sequence? How do you handle rate limits? What happens when one model’s API goes down mid-batch? Chapter 6 turns from the logical architecture to the physical execution. Force multipliers amplify good design and bad design equally. Parallelization, batching, and automation do not care whether they are scaling a solution or scaling a problem. Chapter 6 teaches the engineering discipline that makes the difference: batch design, model selection as an engineering decision, and building infrastructure that survives the model changes that are coming.
- Webb, B. (2026). AI-Assisted Federal Survey Harmonization: Cross-Survey Integration Analysis of 47 Census Bureau Demographic Surveys. Draft working paper. https://github.com/brockwebb/federal-survey-concept-mapper
- Wang, X., Wei, J., Schuurmans, D., Le, Q. V., Chi, E. H., Narang, S., Chowdhery, A., & Zhou, D. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv Preprint arXiv:2203.11171. https://arxiv.org/abs/2203.11171
- Fortier, I., Doiron, D., Little, J., & others. (2011). Is Rigorous Retrospective Harmonization Possible? Application of the DataSHaPER Approach Across 53 Large Studies. International Journal of Epidemiology, 40(5), 1314–1328. 10.1093/ije/dyr106
- Wolf, C., Schneider, S. L., Behr, D., & Joye, D. (2016). Harmonizing Survey Questions Between Cultures and Over Time. In C. Wolf, D. Joye, T. W. Smith, & Y. Fu (Eds.), The SAGE Handbook of Survey Methodology (pp. 502–524). SAGE.
- Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Gupta, S., Majumder, B. P., Hermann, K. M., Welleck, S., Yazdanbakhsh, A., & Clark, P. (2023). Self-Refine: Iterative Refinement with Self-Feedback. Advances in Neural Information Processing Systems 36 (NeurIPS 2023). https://arxiv.org/abs/2303.17651
- Huang, J., Chen, X., Mishra, S., Zheng, H. S., Yu, A. W., Song, X., & Zhou, D. (2024). Large Language Models Cannot Self-Correct Reasoning Yet. Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024). https://arxiv.org/abs/2310.01798
- Xu, W., & others. (2024). Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement. arXiv Preprint. https://arxiv.org/abs/2402.11436
- Pan, L., & others. (2024). Spontaneous Reward Hacking in Iterative Self-Refinement. arXiv Preprint.
- Yang, Z., Zhang, Y., Wang, Y., & others. (2025). A Probabilistic Inference Scaling Theory for LLM Self-Correction. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025).
- Lee, H., & others. (2025). RefineBench: Evaluating Iterative Self-Refinement in Large Language Models. arXiv Preprint.
- Gu, J., Jiang, X., Shi, Z., Guo, J., & others. (2024). A Survey on LLM-as-a-Judge. arXiv Preprint arXiv:2411.15594. https://arxiv.org/abs/2411.15594
- Li, H., & others. (2024). LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. arXiv Preprint arXiv:2412.05579. https://arxiv.org/abs/2412.05579
- Li, D., Jiang, B., Huang, L., Beigi, A., Zhao, C., Tan, Z., Bhattacharjee, A., Jiang, Y., Chen, C., Wu, T., Shu, K., Cheng, L., & Liu, H. (2024). From Generation to Judgment: Opportunities and Challenges of LLM-as-a-Judge. arXiv Preprint arXiv:2411.16594. https://arxiv.org/abs/2411.16594
- Lin, Y., Hasan, M., Kosalge, R., Cheung, A., & Parameswaran, A. G. (2025). TWIX: Automatically Reconstructing Structured Data from Templatized Documents. Proceedings of the ACM on Management of Data. https://arxiv.org/abs/2501.06659