The Graph That Looked Right¶
A team builds a knowledge graph from a corpus of agency reports. Entity extraction, relationship detection, the full pipeline. The graph looks authoritative: nodes, edges, types, a beautiful visualization. Leadership is impressed.
Then someone asks where a specific edge came from. The team traces it back: the LLM inferred a relationship that was implied but never stated in the source text. The inference is plausible. It might even be correct. But there is no passage in any source document that contains that relationship. The graph manufactured evidence.
This is not a failure of the model. The model did what extraction models do: it found patterns. The failure is in the pipeline design. No verification layer. No provenance from edge to source passage. No mechanism to distinguish “extracted from text” from “inferred by model.” The graph that looks right is more dangerous than no graph at all, because it creates confidence without warrant.
Extraction as a Design Problem¶
Extraction is the task family where LLMs pull structured elements from unstructured text. The common operations: entity extraction (names, organizations, locations, codes, dates, amounts from narrative text), relationship extraction (connections between entities), pattern detection (recurring structures, anomalies, signals that match known patterns), and disclosure review assistance (identifying potentially identifying information in data products before release).
What makes extraction different from classification (Chapter 2) and wrangling (Chapter 3): classification assigns categories to items; wrangling corrects and standardizes items; extraction creates new structured data from unstructured input. The output did not exist as structured data before the pipeline ran. This is the most generative of the three domain workflows, and that makes it the most dangerous for verification.
The fundamental tension: extraction is valuable precisely because it produces structured output from unstructured input. But every piece of structured output needs provenance. Where in the source text did this come from? The design challenge is bridging this gap between generative power and verification accountability.
The Confidence Laundering Problem¶
The knowledge graph failure from this chapter’s opening is a specific instance of a general pathology: confidence laundering. Confidence laundering occurs when a pipeline converts uncertain, unverified extraction output into a structured artifact whose format implies verification that never occurred. Typed nodes, labeled edges, and clean visualizations create confidence in the content, but the content was produced by a stochastic process. The structure launders the uncertainty out of the presentation without laundering it out of the data. Downstream users inherit the confidence without the caveats.
Tools that generate hierarchical concept maps from documents and label the output a “knowledge graph” are performing confidence laundering at the terminology level. A concept map organizes topics in a tree structure with implicit “is subtopic of” relationships. A knowledge graph requires typed entities, explicit relationship semantics defined by a schema or ontology, entity resolution across sources, and a queryable graph substrate. The concept map is valuable for human sense-making. Calling it a knowledge graph implies machine-actionable, formally verified knowledge that does not exist in the output. The label creates expectations the artifact cannot satisfy.
Before adopting an extraction tool into your pipeline, ask yourself these questions. If the vendor cannot answer them, that tells you something about the tool’s transparency.
What are the chunking boundaries? Does the tool split text at semantic boundaries (paragraphs, sections, topic shifts) or at mechanical boundaries (page breaks, token counts, character limits)? Mechanical boundaries destroy meaning before extraction begins.
What does the tool call its output? If the tool labels its output a “knowledge graph,” verify whether it produces typed entities with explicit relationships defined by a schema, or a hierarchical concept map with implicit “is related to” links. The label creates expectations. If the output does not meet those expectations, the label is confidence laundering.
Does the tool do entity resolution? If the same entity appears under different names in different source documents, does the tool merge them or create separate nodes? Unresolved entities proliferate the graph with synonyms masquerading as distinct concepts.
Can you trace every output element to its source passage? If the tool produces an entity or relationship, can you see which specific text span it was extracted from? If not, you cannot distinguish extraction from inference.
What model does the tool use, and can you swap it? Extraction quality varies dramatically across models. If the tool locks you into a specific model, you inherit that model’s blind spots with no escape path when the model degrades or is deprecated.
The failure modes, stated plainly:
Garbage chunking. Text split at arbitrary boundaries (by character count or token count rather than semantic structure) instead of natural semantic divisions. A paragraph about household income split across two chunks becomes two incomplete fragments, neither containing the full concept. Downstream extraction from either chunk is necessarily degraded. The chunk boundary destroyed meaning before the extraction even started Chroma, 2024.
Lazy entity resolution. “Census Bureau,” “the Bureau,” “Census,” “U.S. Census Bureau” all become separate nodes in the graph. No coreference handling. The graph now has four entities where there should be one, and every relationship attached to each variant is disconnected from the others. The graph proliferates synonyms as distinct entities.
No validation against source. The extraction pipeline produces an edge: “Agency X funds Program Y.” Does any source document actually state this? Or did the LLM infer it from context? Without provenance from every edge back to its source passage, there is no way to know. The graph becomes an untraceable mixture of extraction and inference.
Structural overconfidence. The graph looks structured. It has types, relationships, properties. This visual structure creates confidence that the content is verified. It is not. The structure is the output of a stochastic process, not a curated knowledge base.
| Failure Mode | SFV Sub-dimension | Consequence |
|---|---|---|
| Garbage chunking | Compression Fidelity (CF) | Semantic boundaries destroyed before extraction begins; fragments produce degraded output |
| Lazy entity resolution | Terminological Consistency (TC) | Synonyms proliferate as distinct entities; relationships fragment across variants |
| No source validation | State Provenance (SP) | Extraction and inference become indistinguishable; graph is unauditable |
| Structural overconfidence | All dimensions | Visual structure creates false warrant; downstream users inherit confidence without caveats |
Chapter 9 introduces State Fidelity Validity (SFV) as a formal framework for assessing whether LLM-powered pipelines preserve the meaning and validity of the data they process. Three of its sub-dimensions apply directly to extraction pipeline design, and it is worth naming them so the connection is clear when Chapter 9 develops the full framework.
Compression Fidelity (CF): Chunk boundary placement destroys meaning. A 500-token chunk that splits a multi-sentence argument loses the argument’s logic. The extraction from the fragment cannot recover what was lost in chunking.
Terminological Consistency (TC): “Household income” becomes five different nodes because different source documents use different terms for the same construct. Without a controlled vocabulary or ontology layer, the graph proliferates synonyms as distinct entities. This is SFV threat T1 (Semantic Drift) operating at the extraction level.
State Provenance (SP): Every node, every edge, every property must trace back to: which source passage, which model version, which prompt, which extraction run. Without this, the graph is a black box that looks like a knowledge base.
The design principle: if you cannot trace every element in your extracted output back to a specific passage in a specific source document, processed by a specific model version with a specific prompt, you do not have a knowledge graph. You have a confabulation graph.
Disclosure Review Assistance¶
The sdcMicro case study illustrates what avoiding confidence laundering looks like in practice: a pipeline that structures the task so the LLM cannot launder what it does not know.
Templ (2026) implemented AI-assisted statistical disclosure control in the sdcMicro R package, used in the Austrian statistical office context. The design is instructive because it gets the boundaries right.
The LLM only sees metadata: variable names, types, categories. Not the actual microdata. It classifies variables as quasi-identifiers and proposes anonymization strategies. The output is reproducible R code, not just a recommendation. The human can inspect exactly what the LLM is proposing before any anonymization is applied.
This is a good design for several reasons. The LLM never sees sensitive data, satisfying the safe data principle from Chapter 12. The LLM proposes, humans review: it does not execute anonymization decisions. The output as inspectable code means the recommendation is transparent and auditable. And the metadata-only pattern reduces both security risk and confabulation risk: the model cannot confabulate relationships in data it never saw.
The metadata-only input pattern is a broader design principle. Every field you do not include in the prompt is a field that cannot be confabulated about. Every dimension of input you withhold from the model is a dimension of stochastic tax you do not pay. Less input surface means less room for confabulation, which means more reliable output. This is confabulation risk reduction applied to extraction pipeline design: fewer input dimensions mean fewer opportunities for the model to generate plausible-sounding wrong answers about fields it should never have seen.
What happens if the LLM misclassifies a direct identifier as a non-identifying variable? What is the downstream consequence for disclosure risk? How would you detect this error before the data product is released?
Chapter 12 develops the principles illustrated here (metadata-only input, LLM-proposes-human-reviews, output as inspectable code) into a complete framework for integrating disclosure review into AI-assisted data workflows.
Scaling Open-Ended Survey Responses¶
DiGiuseppe & Flynn (2026) used LLMs for pairwise comparisons of open-ended survey responses measuring interest-rate knowledge. Six LLMs performed the comparisons. Bradley-Terry models aggregated the results into scales that aligned closely with expert coding.
The key design insight: they did not ask the LLM to assign scores directly. Zero-shot numeric rating without explicit criteria produces unreliable output, not because LLMs cannot make absolute judgments, but because the task gives them no anchor. With a detailed rubric and scoring criteria, absolute rating improves substantially. DiGiuseppe et al. chose pairwise comparison because their construct (interest-rate knowledge) resists simple rubric definition: comparative judgment sidesteps the calibration problem when “better” is easier to specify than “how good.”
Both approaches have failure modes. Pairwise comparison reduces calibration burden but introduces its own biases: LLMs in comparative mode tend to favor verbose, assertive, or confident-sounding responses over accurate but concise ones (Tripathi & others, 2025). A model that correctly declines to answer (the right response when information is insufficient) can score lower than one that confabulates confidently. The choice between absolute and comparative judgment is a design decision, not a universal hierarchy.
| Use pairwise comparison when... | Use absolute scoring when... |
|---|---|
| The construct resists rubric definition | Explicit scoring criteria can be specified |
| Rankings matter more than interval scores | Interval-level measurement is required |
| Pairs are comparable on a single latent dimension | Items should be evaluated independently |
| Reliability-aware aggregation (e.g., Bradley-Terry) is feasible | The item set is too large for exhaustive pairwise comparison |
Six LLMs performed the comparisons, not one. This is ensemble extraction, not single-model extraction. The multi-model pattern from Chapter 5 is the default for extraction tasks — single-model requires explicit justification; it is how you get reliability when ground truth is unavailable. When six independently trained models converge on the same comparative judgment, the signal is meaningful. When they diverge, the divergence tells you something about the construct being measured, not just about the models. This connects to the ensemble patterns in Chapter 5: routing output through multiple independently prompted models, then treating convergence as signal and divergence as a prompt for human review.
Bradley-Terry as the aggregation method is worth noting for the statistical audience. Bradley-Terry assigns each item a score proportional to how often it wins pairwise comparisons, accounting for the strength of its opponents, using the same logic as chess Elo ratings. The result is an interval scale, not just a ranking, which means the distances between scores carry meaning. It is a principled approach to turning pairwise comparisons into interval scales, well-understood in psychometrics and survey research Bradley & Terry, 1952. The LLMs provide the raw comparisons; the statistical model provides the scaling. Each component does what it does well.
If two LLMs disagree on which response demonstrates more knowledge, what does that disagreement tell you? Is it about the responses, the models, or the construct you are trying to measure?
Designing Extraction Pipelines That Earn Trust¶
The design patterns that address confidence laundering, assembled into a coherent extraction pipeline architecture.
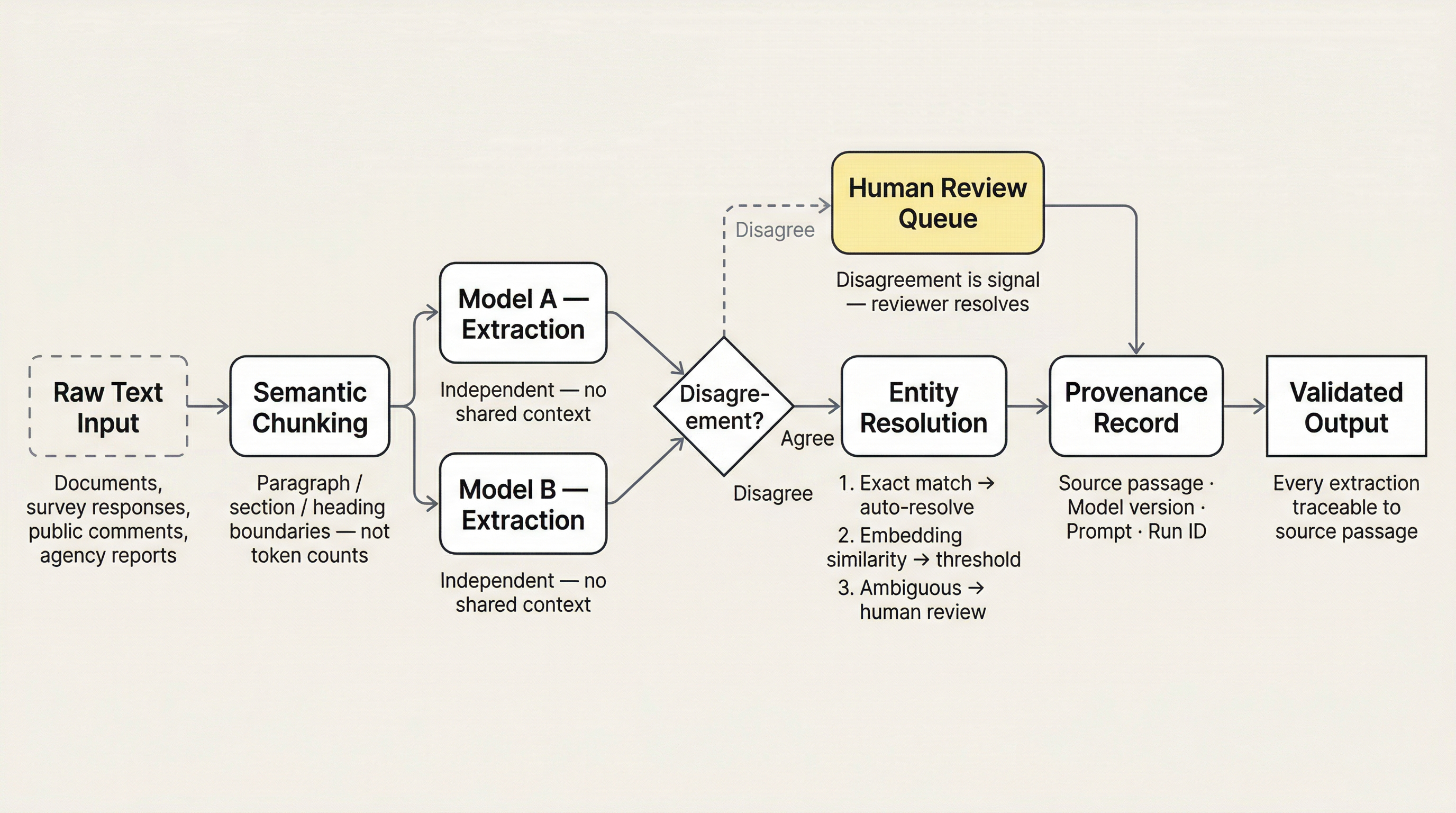
Figure 1:Extraction pipeline architecture. Raw text enters at left. Semantic chunking preserves meaning before extraction begins. Dual-model extraction runs independently; disagreements route to human review. Agreed extractions proceed through entity resolution with escalating ambiguity handling. Every extraction carries provenance to its source passage before reaching validated output.
Chunk at semantic boundaries, not token counts. Use document structure (paragraphs, sections, headings) as chunk boundaries. If the document has no structure, that is a pre-processing problem to solve before extraction begins.
Let the model handle structured formats. The instinct to use regular expressions or rule-based parsers for structured fields -- NAICS codes, dates, phone numbers, addresses -- comes from an era before LLMs could handle these tasks trivially. Today it is usually a false economy, and the reasoning goes deeper than cost.
Regex feels deterministic. It is not. A regex pattern is a bet against the input space: it matches what you anticipated when you wrote it and silently passes over everything else. An address in a name field. A date in an unexpected locale format. A phone number with an extension notation your pattern did not account for. The pattern does not flag these misses. It does not raise an error. It silently produces incomplete results that you trust because “it’s deterministic.” This is a worse failure mode than LLM stochasticity. The LLM’s variance is observable: you can measure agreement rates, flag low-confidence extractions, detect drift. The regex gives you invisible systematic error dressed up as reliability.
The maintenance burden compounds the problem. The author built redaction and extraction pipelines using traditional ML and regex before LLMs were available for these tasks. The result was a brittle mountain of increasingly complex pattern-matching: overfitting to edge cases, breaking on unexpected input formats, requiring specialized knowledge to debug, and consuming more engineering time in maintenance than it ever saved in inference costs. LLMs solved the same problems with a fraction of the effort. Current models already recognize structured formats as part of their training. The cost per extraction is negligible at current pricing. The default recommendation for practitioners: use the LLM. Reserve your engineering effort for the design problems that actually need it -- evaluation infrastructure, confidence routing, provenance tracking -- not for reimplementing pattern matching that the model handles as a side effect of its general capability.
Dual-model extraction with disagreement analysis. Two models extract independently; disagreements are signal. For entity extraction, disagreement on entity boundaries or entity types is especially informative: it tells you where the source text is ambiguous, which is exactly where confabulation risk is highest.
Model selection is a design variable. Extraction quality varies substantially across model families, not just between frontier and small models, but between models of similar size and cost. A model that excels at classification may produce poor extraction output on the same domain. The implication: extraction pipelines need model-specific validation, not just prompt validation. Run your golden questions against each candidate model on your actual extraction task. When you swap models (and model transience guarantees you will), validate before trusting the new model’s extractions.
Provenance from every extracted element to source passage. Not optional. Every entity, relationship, and attribute must carry a citation to the specific text span it was extracted from. If the model cannot point to where it found something, the extraction is inference, not extraction. Label it accordingly.
Controlled vocabulary for entity resolution. Do not let the LLM decide what the canonical entity names are. Provide a reference vocabulary: your agency’s standard codes, your domain’s controlled terms. Map extracted mentions to the vocabulary. Flag mentions that do not match. This is the shared vocabulary principle from Chapter 10 applied at the extraction level.
Entity resolution is an escalation problem, not a single technique. Exact string matching handles the easy cases where surface form is identical or differs only by whitespace and capitalization; automate these. Embedding similarity handles near-miss cases where surface form varies but semantic distance is small: “Census Bureau” and “U.S. Census Bureau” occupy similar embedding space and can be resolved with a similarity threshold. LLM-based disambiguation handles cases requiring semantic understanding of context: an abbreviation that maps to multiple entities depending on context, or two organizations with nearly identical names. The Wikipedia disambiguation pattern is the right mental model for this tier: a page listing all entities that could match an ambiguous term, with enough context to distinguish them. The hardest cases (same name, different entity, context-dependent) require human review. Design the routing explicitly: which cases go to which tier, what threshold triggers escalation, and who reviews the escalated cases.
Human review calibrated to extraction type. Not all extractions need the same review intensity. Direct entity mentions (proper nouns, codes, dates) are higher confidence. Relationship extraction (who funds whom, what regulation applies to what) is lower confidence and needs more review. Design the review queue accordingly.
Recall versus precision tradeoffs explicit in design. For disclosure review: bias toward recall. Catch everything that might be identifying; accept false positives. For entity extraction in analysis: the bias depends on the downstream use. If you are counting organizations, false positives inflate counts. If you are searching for mentions, false negatives miss them. Make the tradeoff decision explicit in the pipeline configuration, not implicit in the prompt.
Extraction cost economics. Extraction prompts are longer than classification prompts. Where a classification task sends a short item and a taxonomy description, an extraction task sends the full source passage, a schema definition, and any reference vocabulary. Per-item cost is higher. Dual-model extraction doubles it. As a rough frame: the classification pipeline in Chapter 2 processed 6,954 survey questions for approximately $15 in API costs. An extraction pipeline processing the same corpus with full-text prompts would cost substantially more per item. The formula: (prompt tokens + completion tokens) × price per token × number of items × number of models. Run this calculation before committing to an architecture. Chapter 14 provides the full cost accounting framework, including when extraction cost justifies fine-tuning or local deployment.
You have budget and engineering time for three of these seven design principles in your first release. Which three do you implement, and why? What risk does each omission create? Which omission is most likely to produce a failure that appears only after the output is in use?
Thought Experiment¶
You are building an entity extraction pipeline to identify organizations mentioned in 10,000 public comments submitted to your agency during a rulemaking. The extracted entities will be used to characterize who commented. Your extraction pipeline identifies “American Medical Association” in 47 comments. An analyst reports this to leadership.
Later, manual review of a sample reveals that 12 of the 47 mentions were actually “American Medical Assistants Association,” “American Medical Women’s Association,” and other similarly-named organizations that the LLM collapsed into AMA. The misattribution inflated the count by 25%.
How would you redesign the pipeline to catch this class of error? What is the consequence if the misattribution reaches a published Federal Register analysis?
The domain workflows trilogy is complete. Chapters 2 through 4 covered three fundamental ways LLMs interact with data: classifying it, correcting it, and extracting structure from it. Each chapter surfaced a common need: multi-model verification, confidence routing, disagreement as signal, provenance from output to input. Chapter 5 generalizes these patterns into the ensemble and multi-model playbook, the cross-cutting architecture that applies to every domain workflow in this book.
- Chroma. (2024). Evaluating Chunking Strategies for Retrieval. https://www.trychroma.com/research/evaluating-chunking
- Templ, M. (2026). AI-Assisted Statistical Disclosure Control with sdcMicro. R package vignette, R Foundation.
- DiGiuseppe, M. R., & Flynn, M. E. (2026). Scaling Open-Ended Survey Responses Using LLM-Paired Comparisons. Public Opinion Quarterly, nfag013.
- Tripathi, T., & others. (2025). Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation. arXiv Preprint arXiv:2504.14716.
- Bradley, R. A., & Terry, M. E. (1952). Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons. Biometrika, 39(3/4), 324–345. 10.2307/2334029