The Nature of the Beast¶
LLM-powered research workflows are stochastic systems operating over language, not numbers. This isn’t a bug. It is a fundamental property of the instrument, and it requires a different design discipline than anything most researchers or data scientists have been trained in.
Large language models are pattern machines. Given an input, they select the best-matching pattern from their training data and generate output accordingly. There is always a probability that the selected pattern doesn’t fit the task at hand. This is not an error in the traditional sense, the way a mistyped formula or an off-by-one index is an error. It is the nature of the instrument. The model did exactly what it was designed to do; the output just happened to be wrong.
This distinction matters because it changes how you design around the problem. You don’t debug stochastic behavior. You design for it.
Statisticians already work with stochastic processes, of course. But the stochasticity of LLMs is qualitatively different from the stochastic processes in the statistical toolkit:
Seeded stochastic processes (Monte Carlo simulation, bootstrap resampling, Markov Chain Monte Carlo (MCMC)) are reproducible via seed, numerical in output, characterizable in distribution, and bounded in uncertainty. Statisticians have decades of theory and practice for designing around these. Set the seed, run it again, get the same result.
LLM stochastic processes are irreproducible across runs (even at temperature=0 on many APIs, as systematic studies have confirmed Ouyang & others, 2025), produce language rather than numbers, exhibit error distributions that are not characterizable in classical terms, and fail in a particularly dangerous way: they produce coherent-sounding wrong answers. The failure mode is not noise around a signal. It is a confident, fluent, plausible-looking wrong answer that passes casual inspection.
This is why we call them stochastic liabilities, not bugs. A bug is a defect you fix. A stochastic liability is a property of the system you design around. You don’t fix the weather; you build a roof.
Every LLM invocation where a deterministic or seed-reproducible method would suffice is unnecessary variance, unnecessary cost, and unnecessary audit burden. We call this the stochastic tax: the overhead you accept every time you route a task through a probabilistic language model. The design discipline this book teaches is, at its core, about minimizing this tax. Not eliminating LLMs, but constraining their use to where they are genuinely needed, and surrounding every invocation with the evidence infrastructure that makes the output defensible.
What Breaks: Reproducibility, Evidence, and State¶
AI for Official Statistics Webb, 2026 (the predecessor to this book) introduced the State Fidelity Validity (SFV) framework in its final chapter, along with the three layers of the reproducibility problem that LLM-assisted research creates: stochastic outputs, prompt sensitivity, and state accumulation failures. If you have read that chapter, the next few paragraphs will be familiar territory. If you haven’t, what follows is self-contained.
Traditional reproducible research rests on a simple contract: same data plus same code equals same results. With LLMs in the pipeline, that contract is broken. Same prompt plus same model does not equal same output. The classical evidence chain, the one that lets a reviewer trace a published number back through code to data, has a gap in it now.
This does not mean evidence is impossible. It means you need a different kind of evidence chain. Not “reproduce the exact output” but “demonstrate the process was sound and the result is defensible.” You need to show what models were used, what prompts were sent, what confidence scores came back, how disagreements were adjudicated, and what the decision rule was for accepting a result. This is what SFV operationalizes, and Chapters 9 and 10 go deep on the framework and the engineering required to support it.
State must be actively managed. Context windows are mutable, lossy, and subject to drift. In a long-running pipeline, the instrument literally changes under you as context accumulates, gets truncated, or gets summarized. The terminology drift problem, where a model starts using slightly different terms for the same concept as a session progresses, is one example of a broader class of state management challenges.
Variance compounds through pipelines. A single stochastic node introduces manageable variance. Chain five of them in sequence and you have a variance amplification problem. Each node’s output becomes the next node’s input, and the uncertainty propagates. This is the multi-stage design challenge that Chapters 5 through 8 address: ensemble methods, parallelism patterns, checkpoint design, and evaluation infrastructure.
The Iterative Refinement Trap¶
A common response to LLM unreliability is to add a refinement loop: generate an output, evaluate it, revise, repeat. This is intuitive and sometimes effective. It is also a trap.
The core problem is that when the evaluator shares the generator’s blind spots, iteration rearranges errors without removing them. Huang et al. (2024) demonstrated this directly: large language models cannot self-correct reasoning when no external signal is provided. The model’s internal critic has the same training data, the same biases, and the same failure modes as the generator. Asking it to evaluate its own work is asking the student to grade their own exam.
The empirical picture is consistent. Madaan et al. (2023) showed diminishing returns in iterative self-refinement, with the largest improvements concentrated in the first one or two rounds. Yang et al. (2025) formalized the convergence ceiling: there is a maximum accuracy a self-refinement loop can reach regardless of how many iterations you run, determined by the model’s ability to preserve correct content while fixing errors. This ceiling is a mathematical property of the system, not a tuning problem.
The pathologies go deeper than diminishing returns. Xu & others (2024) documented self-bias amplification: LLMs systematically overrate their own generations, and this bias amplifies monotonically over multiple self-refinement steps. The model becomes more confident in its own output with each iteration, not more accurate. Pan & others (2024) identified reward hacking in self-refinement: when the generator and evaluator are the same model, the generator learns to exploit the evaluator’s preferences rather than improving output quality. And the RefineBench benchmark (Lee & others (2025)) put numbers on the gap: state-of-the-art models show at most 1.8 percentage points of gain from self-refinement across five iterations, but near-perfect gains when guided by external feedback.
Machines can overthink problems too. The design implication is clear: self-refinement loops need explicit stopping criteria, external validation signals, and architectural awareness that the model’s critic shares the model’s blind spots. This connects directly to the ensemble approach in Chapter 5. Use different models to evaluate each other, not the same model evaluating itself.
There is a structural resemblance between inference-time self-refinement degradation and training-time model collapse. Model collapse occurs when models are trained recursively on their own outputs, progressively degrading until the model becomes useless Shumailov et al., 2024. Self-consuming generative models, as Alemohammad et al. (2023) demonstrated, go “MAD” (Model Autophagy Disorder), they lose diversity and converge on a narrow subset of their output space. At inference time, iterative self-refinement exhibits a structurally similar dynamic: the system consumes its own output, amplifies its own biases, and converges on increasingly confident but not increasingly correct answers.
The mechanisms are different. Training-time collapse involves weight updates on synthetic data eroding the learned distribution. Inference-time degradation involves context window pollution and the model’s inability to reliably evaluate its own output; no weights change. But the pattern is shared: recursive self-consumption degrades output quality. The practical implication is the same in both cases: external signal is the remedy. Fresh training data prevents model collapse; external evaluation prevents self-refinement degradation. Design accordingly.
Have you built a refinement loop that seemed to improve output at first, then plateaued or got worse? What signal finally told you the iterations were no longer helping? If you have not experienced this yet, consider: how would you know?
Five degradation pathways are now documented in the literature. Diminishing returns: self-refinement gains concentrate in the first iteration and plateau rapidly (Madaan et al., 2023). Convergence ceiling: a mathematical bound on achievable accuracy regardless of iteration count (Yang et al., 2025). Self-bias amplification: models systematically overrate their own output, and the bias grows with each iteration (Xu & others, 2024). Reward hacking: when generator and evaluator are the same model, the generator exploits the evaluator’s preferences (Pan & others, 2024). Recursive self-consumption: the structural parallel to training-time model collapse, where iterative self-refinement degrades output diversity and quality (Shumailov et al., 2024Alemohammad et al., 2023). All five pathways share one remedy: external signal.
There is a sixth failure mode that operates at a different level. The evaluation trap is not about self-refinement loops but about how teams allocate evaluation effort. The pattern: a team spends months comparing five models on generic benchmarks, producing a detailed comparison report. By the time the report is ready, two of the models have been updated, one has been deprecated, and a new contender has entered the market. The conclusions are obsolete before publication. The cost is not API fees; it is researcher time consumed by evaluation activities that do not produce actionable results for the specific pipeline. Chapter 6 addresses this directly through model selection as an engineering decision, and Chapter 8 inverts it: instead of exhaustive comparison on generic benchmarks, build evaluation infrastructure that tests your pipeline on your data after every change.
Think about the last time your team compared AI tools or models. How long did the evaluation take? Were the results still valid by the time the report was finished? What would have happened if you had spent that time building evaluation infrastructure for your specific pipeline instead?
The Systems Engineering Gap¶
Statisticians and data scientists are trained in methods, not architectures. They know how to specify a model, evaluate its fit, and interpret its output. They are not trained in systems engineering: how to design pipelines with checkpoint and recovery, how to manage state across distributed processes, how to build evidence chains that survive audit, or how to make architectural decisions that trade off cost against reliability.
In the author’s assessment, the tooling market is not filling this gap. The market is building for software development: code generation, DevOps automation, customer service chatbots, content generation. Research documentation, scientific practice, provenance tracking, validity frameworks, these are niche concerns that serve a small market. The LLM-specific tools researchers need (orchestration with research-grade provenance, evaluation infrastructure for stochastic pipelines, state management for mutable instruments) are not being built because the market that would pay for them is too small to attract commercial investment.
The community has to fill this gap, or it won’t get filled.
“Just call the API” is not a design methodology. It is the starting point for every project that will eventually be rebuilt from scratch when the first approach fails at scale, fails to reproduce, or fails an audit. The false economy of skipping design is that you will rebuild it anyway, but now with accumulated technical debt, no evidence chain, and colleagues who have already lost confidence in the approach.
Levels of AI Automation in Research¶
Shapiro (2026) proposed five levels of AI coding automation, modeled after NHTSA’s five levels of driving automation. The levels range from “spicy autocomplete” (Level 0, AI suggests the next line) through “junior developer” (Level 2, AI navigates multi-file changes but the human reviews everything) to “the dark factory” (Level 5, autonomous software production from specs). Shapiro’s key insight: every level past 2 “feels like you are done. But you are not done.” He estimates 90% of developers using AI tools are stuck at Level 2.
The framework translates to research workflows, but with a critical difference. Software verification at Level 5 is “do the tests pass?” Research verification at Level 5 is “is this defensible as official statistics?” The second question requires validity, provenance, and institutional credibility. It cannot be reduced to a pass/fail check.
For research workflows, the levels look roughly like this:
Levels 0 and 1: LLM as helper. You ask it for VBA code to QA 3,000 Excel files. You check its work. Real value, limited scope, limited risk. Most people should start here for most tasks.
Level 2: LLM as junior analyst. It does multi-step work, you review everything. You are faster, but you are the bottleneck. This is “micromanager mode,” and it is where most AI-assisted research work sits today.
Level 3: Outcome-based. You have built the infrastructure: dual-path verification, evidence chains, provenance tracking, statistical quality checks. You do not read every line of output because the system tells you where the problems are. You have moved yourself to where you provide the most value: validation, domain judgment, the critical 10%.
Levels 4 and 5: Specification-driven research pipelines. You write the research design spec, the system executes, you evaluate whether the outputs are defensible. The verification framework is the intellectual property, not the outputs themselves.
The argument for this book is that the levels exist for research workflows, but the infrastructure to operate safely at the higher levels does not exist yet for this context. As of this writing, the tooling market is building Level 3+ infrastructure for software developers: test suites, CI/CD, type systems. For research workflows, the equivalent infrastructure (SFV, artifact tracking, dual-path verification, evidence chains) has to be built by the people who need it. This book teaches you how.
There is empirical support for the gap between perceived and actual productivity at these levels. A randomized controlled trial by METR Becker et al., 2025 studied 16 experienced open-source developers on 246 real tasks with AI tools. The tools slowed their work by 19% on average. Before starting, developers forecasted AI would make them 24% faster. After completing the study, having actually been slowed down, they still estimated AI had helped by 20%. They were wrong about both direction and magnitude, and direct experience did not correct the error. The tool changed; the workflow did not. Moving up through the levels requires more than a better tool. It requires redesigning how you work.
This perception gap is not limited to a small-sample study. The 2024 Accelerate State of DevOps Report DORA Team, Google Cloud, 2024, a large-scale global survey of technology professionals, found the same pattern at scale: 75% of developers self-reported productivity gains from AI tools, while measured delivery metrics told a different story. Every 25% increase in AI adoption correlated with a 1.5% dip in delivery speed and a 7.2% drop in system stability. The METR result is the RCT; the DORA result is the large-sample observational confirmation. Together they establish that the gap between perceived and actual AI-assisted productivity is robust across methodologies and sample sizes. When people report that AI has accelerated their work, the evidence suggests they may be wrong about both the direction and the magnitude of the effect.
The Bottleneck Has Moved¶
The efficiency and accuracy of AI coding tools at producing working code is improving rapidly. The trajectory is clear: the mechanical act of translating a design into functioning software is becoming a smaller fraction of the total intellectual effort. This does not mean coding is trivial. It means coding is no longer where practitioners provide their most irreplaceable value.
What remains, and what is growing in importance, is the work that surrounds the code: the design documentation that specifies what the system should do and why; the drift prevention that ensures the system continues to do it correctly over time; the fidelity assurance that validates outputs against known standards; and the evidence chain that makes every decision auditable. Your job is not to be an expert programmer. Your job is to provide expert oversight: knowing how, when, and where to deploy the tools, how to monitor their output appropriately, and when to intervene.
This requires a deliberate discipline: automate yourself out of every loop where you do not add unique value. Place the human in the loop at the right point, at the right time, where they provide maximum value. Every validation step that a human performs where a deterministic check would suffice is wasted effort. Every deterministic check that substitutes for human judgment where domain expertise is required is a false economy. Working at speed and scale demands getting this allocation right.
The empirical evidence supports this framing from both sides. The METR study Becker et al., 2025 showed that developers who adopted AI coding tools without redesigning their workflow actually slowed down, because they were still operating as the bottleneck at Level 2 rather than restructuring around where they add value. From the failure side, Shapira et al. (2026) deployed autonomous LLM agents with full tool access (shell, email, file systems, persistent memory) in a live environment and found that the agents could write code, install packages, and execute system commands with reasonable competence. What they could not do was the oversight layer: they lacked stakeholder models (no concept of who they served or who might be affected), lacked self-models (no awareness of when they exceeded their competence), and routinely misrepresented their own state (reporting tasks as complete when the underlying system state contradicted those reports). The coding was the easy part. The governance, the accountability, the state verification: that was where everything broke.
The same dynamic applies to research workflows. A well-designed pipeline scaffolds the practitioner’s judgment: it surfaces the right information at the right time, flags anomalies, structures decisions. A badly designed one offloads the judgment entirely, and the human becomes a rubber stamp. Cognitive science distinguishes between cognitive offloading (the system does the thinking for you) and cognitive scaffolding (the system structures your thinking without replacing it). The difference matters because of a phenomenon called the expertise reversal effect Kalyuga et al., 2003: what works as productive offloading for an expert (freeing cognitive resources for novel aspects of a problem) actively harms a novice (preventing construction of the foundational knowledge needed to catch errors). A senior statistician can safely delegate routine classification to an LLM because they have the mental schemas to catch errors. A junior analyst using the same workflow without those schemas will miss errors the senior would catch immediately. The same pipeline can be safe for one operator and dangerous for another. Education research confirms the asymmetry: students given unrestricted AI assistance improved short-term task scores by 48% but performed 17% worse on subsequent tests without AI access Bastani et al., 2024. The tool produced the output; the understanding did not form. Workflow design must account for this.
What’s Wrong With This Picture?¶
Consider the simplest possible LLM workflow:
The naive workflow. Input goes in, model processes it, output comes out.
This is how most people start. One model, one call, one result. It works, in the sense that you get output. Now ask yourself:
What could go wrong here?
How would you know if the output was wrong?
Could you defend this result to a reviewer? To an auditor? To Congress?
What happens when you run it again tomorrow and get a different answer?
What happens when the model provider updates the model next month?
These are not rhetorical questions. They are the actual engineering problems the rest of this book addresses. Take a moment with them before reading on.
Now consider the designed version of the same workflow:
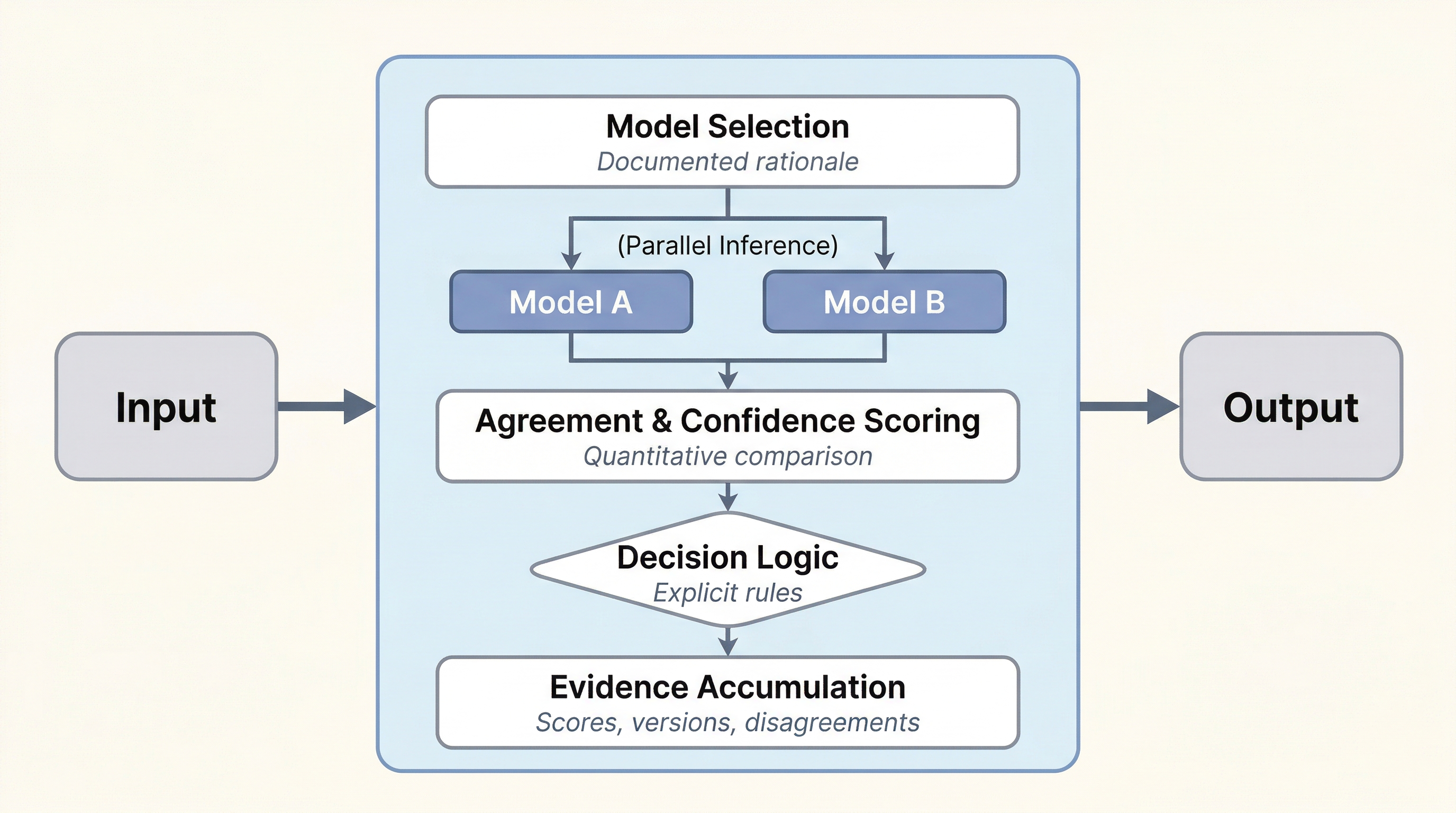
The designed workflow. Same input, same output, but now you can defend it.
Same input, same output. But every component exists because it solves one of the problems you just identified. The model selection layer exists because you need to reason about your instrument. The parallel inference exists because a single stochastic output is not trustworthy. The agreement scoring exists because you need a quantitative basis for confidence. The decision logic exists because “pick one” is not a defensible rule. The evidence accumulation exists because you cannot defend a result without a record of how it was produced.
The chapters that follow address each of these components: ensemble patterns (Chapter 5), evaluation infrastructure (Chapter 8), state management and provenance (Chapters 9 and 10).
The Evaluation Trap¶
People who want to spend six months comparing Model A versus Model B are doing 2024 work on a 2026 landscape. By the time you finish your comparison study, the models have changed. New releases, new fine-tunes, new pricing, new capabilities. The landscape shifts weekly.
The design discipline is not “pick the right model.” It is: build the evaluation harness. Design the infrastructure that lets you evaluate any model against your task, swap models without rewriting code, and compare performance across versions over time. Your architecture should be model-agnostic at the inference layer.
This is why Chapter 8, Evaluation by Design, exists. It teaches the evaluation process and the infrastructure that supports it, not specific model recommendations that would be stale before the ink dries.
Removing Yourself from the Loop (Carefully)¶
The conventional wisdom is that humans must be in the loop. This is correct but incomplete. Being in the loop everywhere is waste. It is Level 2 thinking: the human as micromanager, reviewing every output, unable to scale beyond what one person can read in a day.
The design discipline is identifying where in the loop human judgment is irreplaceable, and building automation for everything else. The goal is not to remove human accountability. It is to remove human busywork so that expert attention goes where it provides the most value: the ambiguous cases, the disagreements, the edge conditions that require domain knowledge no model has.
This requires prework. You can only step back from the loop because you built the systems that make stepping back safe: dual-path verification that catches discrepancies before they reach you, evidence chains that let you audit any result after the fact, provenance tracking that tells you exactly what happened and why, statistical quality checks that flag anomalies without requiring you to read every record. Level 3 is earned, not assumed. You get there by doing the prework.
Where in your current workflow are you the bottleneck -- reviewing every output because you do not trust the system to flag its own problems? What would it take to build enough infrastructure that you could step back from that loop and focus on the cases that actually need your judgment?
The Prework¶
The prework is what this book teaches. The design discipline, the engineering patterns, the infrastructure. It is not overhead. It is what lets you go fast safely.
Without the prework, you have two options. Go slow: stay at Level 2, micromanage every output, and accept that your throughput is bounded by how fast one person can review. Or go fast and break things, which in official statistics is not acceptable. The numbers that come out of federal statistical agencies are trusted because they are defensible. That trust is not compatible with “move fast and break things.”
The prework is the third option. Go fast and be defensible, because you built the systems that produce the evidence chain automatically. Every pattern in the chapters that follow is part of this prework. Ensemble architectures that detect disagreements before they become errors. Checkpoint systems that let you recover from failures without losing work. Evaluation infrastructure that produces quality metrics as a byproduct of production, not a separate effort. Provenance systems that record what happened so you can prove it later.
None of this is easy. The honest version is that even with the prework, even with the design discipline, you will still make mistakes. The difference is that with the infrastructure in place, you catch them faster, recover from them cheaper, and can prove to a reviewer that the mistakes were caught and handled.
The Organizing Framework¶
The design patterns in this book are organized around two paired layers: compressed tenets and working principles. These are not aspirational statements drafted in a conference room. They emerged from doing the work, from building real systems for federal statistical agencies and learning what mattered through failure.
Compressed Tenets¶
The tenets define what matters. They are the strategic alignment layer, the answer to “what are we optimizing for?”
Trust defines the mission. Statistical agencies exist because the public trusts their numbers. Every design decision must protect that trust.
Data precedes models. Understand your data before selecting your model. The data’s structure, quality, and provenance constrain what any model can do.
Deliver capability quickly. A working pipeline that ships is worth more than a perfect architecture that doesn’t. Iterate on deployed systems.
Governance must enable execution. Governance that prevents delivery is not governance; it is obstruction. Design controls that enable work, not block it.
Humans remain accountable. No model makes final decisions. Humans own the output, the interpretation, and the consequences.
Defensibility is required. Every result must be traceable to its inputs, methods, and decision rules. If you can’t defend it, don’t publish it.
Adapt continuously. The model landscape, the threat landscape, and the requirements landscape all change. Design for change.
Build internal capability. Don’t outsource understanding. The people operating the system must understand the system.
Experiment under control. Try new approaches, but within a framework that captures what you tried, what happened, and what you learned.
Infrastructure enables delivery. You cannot deliver capability without the platforms, tools, and environments to support it.
Working Principles¶
The working principles define how to act. They are the practitioner layer, the answer to “what do I do on Monday morning?”
If it cannot be explained, do not use it. Explainability is not optional. If you cannot explain to a non-technical stakeholder why the system produced a particular output, the system is not ready.
Slow governance prevents delivery. Governance processes that take months to approve a model or a pipeline are governance failures. Risk-based controls, not exhaustive review.
Adoption determines impact. A tool nobody uses has zero impact regardless of its technical merit. Design for the people who will actually use it.
Build lineage before scale. Before you process a million records, prove you can trace one record through the entire pipeline. Provenance first, scale second.
Reuse data before collecting more. Most organizations are data-rich and analysis-poor. Use what you have before asking for more.
Access defines capability. You cannot use what you cannot reach. Data access, compute access, and model access are prerequisites, not afterthoughts.
Security is a system property. Security is not a feature you bolt on at the end. It is a property of the system architecture, present in every design decision.
Outputs require full provenance. Every output must be traceable to its inputs, the models used, the prompts sent, the confidence scores returned, and the decision rules applied.
These tenets and principles map to specific chapters. Each chapter operationalizes one or more of them. The full mapping is in the Appendix.
What This Book Covers¶
The chapters that follow are organized in five phases.
Chapter 1 (this chapter) is the Foundations phase: the nature of the instrument, the stochastic liabilities that shape every design decision, and the organizing framework of tenets and working principles.
Chapters 2 through 4, the Domain Workflows phase, cover domain workflow patterns: classification and coding (with the Federal Survey Concept Mapper as anchor case study), data wrangling and standardization, and detection and extraction. These chapters are about specific types of work that statistical agencies do, and the design patterns that make LLM-assisted versions of that work reliable.
Chapters 5 through 8, the Cross-Cutting Patterns phase, cover cross-cutting engineering patterns: ensemble and multi-model architectures, parallelism and batch design, checkpoint and recovery, and evaluation infrastructure. These are the “how” chapters that apply across every domain workflow.
Chapters 9 and 10, the Validity phase, cover state and provenance: the SFV framework applied to workflow design, and the engineering of state management and research artifact tracking. These chapters address the question of how you know your system is still doing what you think it’s doing, and how you prove it.
Chapters 11 through 14, the Delivery phase, cover operational concerns: workflow orchestration and the tool landscape, security and supply chain risks, deploying in institutional environments, and cost engineering. These chapters address the reality that building a working pipeline is only half the problem; operating it in a real organization with real constraints is the other half.
Each chapter is designed to stand alone. You can read them in order for the full argument, or jump to the chapter that addresses your immediate problem. The tenets and working principles provide the connective tissue.
Thought Experiment¶
Your team has built an LLM pipeline that classifies survey responses into standardized categories. It ran overnight on 50,000 records. The summary statistics look reasonable: the distribution across categories matches historical patterns, the processing cost was within budget, and no errors were logged.
How do you know the model didn’t silently change its classification criteria at record 23,000? How do you know a prompt that worked correctly on English-language responses didn’t mishandle the Spanish-language subset? How do you know that “reasonable summary statistics” aren’t masking a systematic error that happens to preserve the aggregate distribution while misclassifying individual records?
If you cannot answer these questions with your current infrastructure, you know where to start reading.
The next chapter takes the first domain workflow, classification and coding, and shows these design principles in action against a real problem with real data and a real cost constraint.
- Ouyang, S., & others. (2025). Non-Determinism of “Deterministic” LLM System Settings in Hosted LLMs. Eval4NLP 2025. https://aclanthology.org/2025.eval4nlp-1.12.pdf
- Webb, B. (2026). AI for Official Statistics. Zenodo. 10.5281/zenodo.19206379
- Huang, J., Chen, X., Mishra, S., Zheng, H. S., Yu, A. W., Song, X., & Zhou, D. (2024). Large Language Models Cannot Self-Correct Reasoning Yet. Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024). https://arxiv.org/abs/2310.01798
- Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Gupta, S., Majumder, B. P., Hermann, K. M., Welleck, S., Yazdanbakhsh, A., & Clark, P. (2023). Self-Refine: Iterative Refinement with Self-Feedback. Advances in Neural Information Processing Systems 36 (NeurIPS 2023). https://arxiv.org/abs/2303.17651
- Yang, Z., Zhang, Y., Wang, Y., & others. (2025). A Probabilistic Inference Scaling Theory for LLM Self-Correction. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025).
- Xu, W., & others. (2024). Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement. arXiv Preprint. https://arxiv.org/abs/2402.11436
- Pan, L., & others. (2024). Spontaneous Reward Hacking in Iterative Self-Refinement. arXiv Preprint.
- Lee, H., & others. (2025). RefineBench: Evaluating Iterative Self-Refinement in Large Language Models. arXiv Preprint.
- Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI Models Collapse When Trained on Recursively Generated Data. Nature, 631(8022), 755–759. 10.1038/s41586-024-07566-y
- Alemohammad, S., Casco-Rodriguez, J., Luzi, L., Humayun, A. I., Babaei, H., LeJeune, D., Siahkoohi, A., & Baraniuk, R. G. (2023). Self-Consuming Generative Models Go MAD. arXiv Preprint arXiv:2307.01850. https://arxiv.org/abs/2307.01850
- Shapiro, D. (2026). The Five Levels: From Spicy Autocomplete to the Dark Factory. danshapiro.com. https://www.danshapiro.com/blog/2026/01/the-five-levels-from-spicy-autocomplete-to-the-software-factory/
- Becker, J., Rush, N., Barnes, E., & Rein, D. (2025). Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. arXiv Preprint arXiv:2507.09089. https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
- DORA Team, Google Cloud. (2024). Accelerate State of DevOps Report 2024. Google Cloud. https://dora.dev/research/2024/dora-report/
- Shapira, N., Wendler, C., Yen, A., Sarti, G., Pal, K., Floody, O., Belfki, A., Loftus, A., Jannali, A. R., Prakash, N., Cui, J., Rogers, G., Brinkmann, J., Rager, C., Zur, A., Ripa, M., Sankaranarayanan, A., Atkinson, D., Gandikota, R., … Bau, D. (2026). Agents of Chaos. https://arxiv.org/abs/2602.20021
- Kalyuga, S., Ayres, P., Chandler, P., & Sweller, J. (2003). The Expertise Reversal Effect. Educational Psychologist, 38(1), 23–31. 10.1207/S15326985EP3801_4