Everything Fails¶
Your pipeline will fail. The network will drop. The API will return an error. The provider will update the model under you. Your coding assistant will ignore your config file and hardcode a parameter the target model does not accept, and the pipeline will fail silently at record 30,000 of 50,000.
The question is never “will something go wrong?” The question is: when something goes wrong, does the system recover gracefully, or do you start over from scratch?
Chapter 6 built the parallel batch architecture. This chapter makes it survivable. Config-driven design prevents the failures you can anticipate. Progressive test infrastructure catches the failures before they reach production scale. Checkpoint and recovery architecture handles the failures that get through anyway. And because the tools you use to build these pipelines are themselves stochastic, the same discipline applies to the development process.
Config-Driven Architecture¶
This is reproducible research discipline applied to LLM pipelines. The audience for this book already knows the principle: save the random seed, never hardcode parameters, put all configurable values in a file so settings are transparent, auditable, and modifiable without touching source code. The same discipline applies here, extended to every parameter that affects pipeline behavior.
Never Hardcode¶
Never hardcode. Model names, API endpoints, temperature and other model-specific parameters, batch sizes, worker counts, retry limits, checkpoint intervals: all of these belong in a configuration file. The config file makes settings visible, ranges clear, and modifications trackable. When results change between runs, the config file is your first diagnostic tool: what was the setting, and did you change it, or did the provider change something on their end?
Parameter Interfaces Have a Shelf Life¶
Model parameters have a shelf life. Different models expose different tunable parameters: temperature, top-p, frequency penalty, and others. Practitioners should understand what parameters are available for their chosen model and what they control. But those parameters can disappear between model versions. When providers introduced reasoning-focused model architectures, temperature is fixed at 1 and not user-controllable; the API accepts the parameter but silently overrides it. Practitioners who had invested time finding optimal temperature settings for specific tasks had that work invalidated by a model architecture change. The parameter interface itself has a shelf life.
Temperature as a Bias-Variance Tradeoff¶
The temperature tradeoff as bias-variance. Temperature (or “creativity” in some interfaces) controls output variance. High temperature produces more diverse outputs: potential for creative connections and useful leaps, but also higher error rates. Low temperature produces more deterministic, conservative outputs: safer for structured research tasks, but potentially missing useful patterns. This is the Type I / Type II error tradeoff that statisticians already understand: trading sensitivity for specificity. The right setting depends on the task. The point is that this is a real engineering tradeoff, not a magic number, and it belongs in configuration where it is visible, adjustable, and documented.
Training Cutoff Contamination¶
Training cutoff contamination. The AI coding assistant’s knowledge of available models and APIs is frozen at its training cutoff. It suggests deprecated models, uses outdated API signatures, hallucinates model names that do not exist. You can use services to inject current context about what is available, but the model may still resist. The config file becomes an enforcement mechanism, not a suggestion: you do not ask the model what to use, you tell it via configuration, and you validate that it actually used what you told it to use.
Silent Failures¶
Silent failures. The author experienced pipeline failures caused by the AI coding assistant hardcoding model parameters that conflicted with the configuration file. The coding assistant injected parameters the target model did not accept, or substituted model names from its training data that did not match the configured model. The API did not throw a hard error. It silently misbehaved. Troubleshooting required working backwards from unexpected results to find the parameter mismatch. A runtime validation check, verifying that the parameters being sent are actually accepted by the target model and that the model name matches the config, would have caught it immediately.
Config-driven architecture is a defense against both runtime failures and development-time drift. If model names, endpoints, and pipeline parameters live in configuration, the AI coding partner cannot hardcode them without the deviation being immediately visible.
Look at a pipeline you have built or are building. How many parameters are hardcoded in the source? If a model name or API endpoint changed tomorrow, how many files would you need to edit?
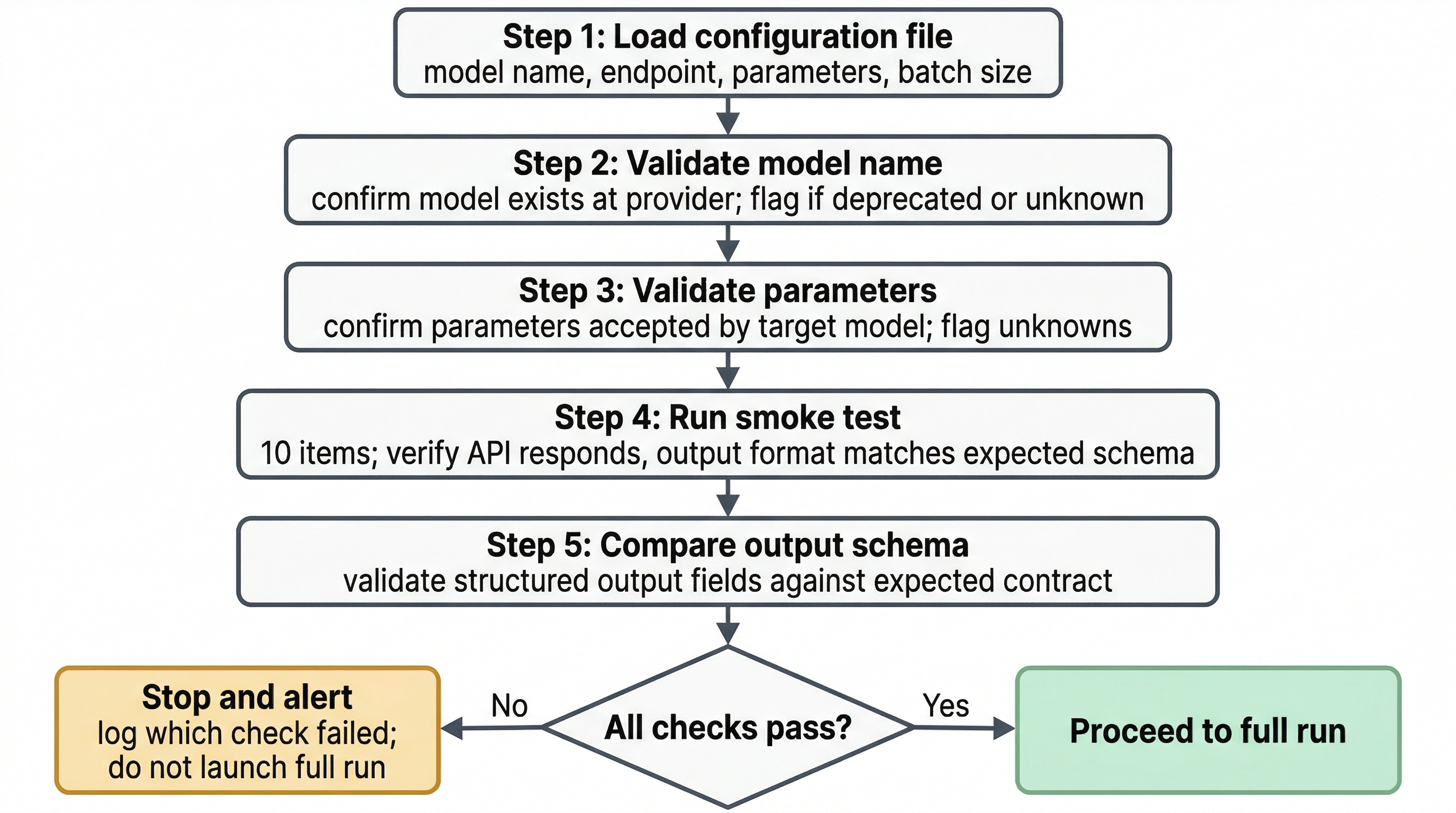
Figure 1:Config validation flow before full pipeline launch. Each check gates the next. A failed model name, unaccepted parameter, or failed smoke test stops the run before it processes 50,000 records on bad configuration. The cost of the smoke test is minutes; the cost of discovering a config error at record 40,000 is hours.
Progressive Test Infrastructure¶
Testing is not a phase after development. It is infrastructure you build alongside the pipeline, incrementally. This is the NIST AI RMF’s Test, Evaluation, Verification, and Validation (TEVV) National Institute of Standards and Technology, 2023 operationalized: continuous, not a gate at the end.
The audience for this book may not come from a software engineering background. A few definitions:
A unit test is a small, isolated check that one specific thing works. Does the JSON parser handle the model’s output format correctly? Does the confidence score extractor return a float between 0 and 1? One function, one check, pass or fail.
A smoke test is a quick sanity check before committing to the full run. Run 10 API calls before launching 50,000. Does the model respond? Does the output format match what you expect? Are the parameters accepted? Think of it as turning the key and seeing if the engine starts before driving across the country.
A regression test is an automated check that re-runs your test suite after any change to see if something broke. You had 47 passing tests yesterday, you changed the model config today, now 3 tests fail. Something in the change broke something that was working. The regression test catches it before the broken pipeline processes 50,000 records.
Concrete examples that earn their place. Validate the model name against the config before any API calls fire. Validate that parameters being sent are accepted by the target model. Run a small batch (10 items) as a smoke test before launching the full run. Compare smoke test output format against the expected schema. Run automated test suites on any config change to catch silent breakage.
The argument for automation. If you are manually inspecting pipeline outputs, you are slow, inconsistent, and you will miss things. If the checks are automated, they run the same way every time, and deviations surface immediately. You do not want to validate and inspect everything yourself. That takes enormous time and does not scale. Automating the process makes it consistent and gives you a better chance of catching drift in the system or system state. Chapters 9 and 10 treat drift detection and state management in depth.
The goal is not to teach software testing methodology. It is to convince practitioners that a small investment in test infrastructure prevents large downstream failures, and to give them the vocabulary to work productively with software engineers who have deeper expertise in this domain.
You update your pipeline’s model configuration from Model A to Model B. What is the minimum set of checks you would run before processing your full dataset? How long would those checks take versus the time you would lose troubleshooting a silent failure at record 40,000?
Error Classification and Retry Logic¶
Not all errors are the same. Your pipeline’s response to a failure should depend on what kind of failure it is.
Transient errors: retry. API rate limit hit, network timeout, temporary server error (HTTP 429, 503). These resolve themselves. Exponential backoff with jitter (introduced in Chapter 6) is the standard response. Set a maximum retry count to avoid infinite loops.
Permanent errors: escalate. Invalid API key, model deprecated, endpoint removed, malformed request that will never succeed. Retrying is pointless. Log the error with full context, stop the affected batch, alert the operator. Do not burn API credits retrying something that will never work.
Data errors: log and continue. The input is malformed, the model returns an unparseable response, the structured output does not match the expected schema. Log the failure with the input that caused it, skip the record, continue processing. These are quality signals: they tell you something about your data or your prompt, not about the infrastructure. Review them in batch after the run completes.
Table 1:Error classification and pipeline response. The key design decision is that the pipeline must classify each error type and respond differently. Retrying permanent errors wastes resources. Stopping on data errors prevents completion. Ignoring transient errors produces incomplete results. Error type determines response.
| Error Type | Examples | Pipeline Response | Investigation Priority |
|---|---|---|---|
| Transient | HTTP 429 (rate limit), network timeout, HTTP 503 | Retry with exponential backoff and jitter; stop after max retry count | Low — self-resolving; escalate only if max retries exceeded |
| Permanent | Invalid API key, deprecated model, removed endpoint, malformed request | Log with full context; stop affected batch; alert operator immediately | High — immediate; do not retry |
| Data | Malformed input, unparseable model response, schema mismatch | Log failure with input; skip record; continue processing | Medium — review in batch after run; quality signal, not infrastructure signal |
The key design decision: the pipeline should classify each error and respond appropriately, not treat all failures the same way. A pipeline that retries permanent errors wastes resources. A pipeline that stops on data errors never finishes. A pipeline that ignores transient errors produces incomplete results.
Idempotent operations. An operation is idempotent if running it twice produces the same result as running it once. For LLM pipelines, this means: if a batch is retried after a transient failure, it should not produce duplicate results, corrupt state, or double-count records. Design your write operations (saving results, updating checkpoints) so that re-execution is safe.
Checkpoint and Recovery Architecture¶
Long-running batch jobs fail. The engineering question is whether they recover gracefully.
Chapter 6 introduced the requirement: the Concept Mapper Webb, 2026 saved progress every 10 questions with transaction-safe file writes. This section provides the full architectural treatment.
Checkpoint granularity. How often do you save state? Every record is expensive in I/O overhead. Every 1,000 records means losing up to 999 records of work on failure. The right interval depends on how expensive each record is to process and how often failures occur. For the Concept Mapper’s dual-model classification at approximately $0.002 per question, losing 10 questions of work (two cents) was acceptable. For a pipeline processing expensive documents at $0.50 each, checkpoint every record.
What to checkpoint. At minimum: which records have been successfully processed, the results for those records, and enough state to resume from the next unprocessed record. The checkpoint file is a recovery contract: it tells the pipeline exactly where to pick up.
Transaction-safe writes. Write the new checkpoint to a temporary file, then atomically rename it to the checkpoint file. If the process crashes mid-write, the old checkpoint is still intact. Never write directly to the checkpoint file. A crash during write corrupts it and you lose everything.
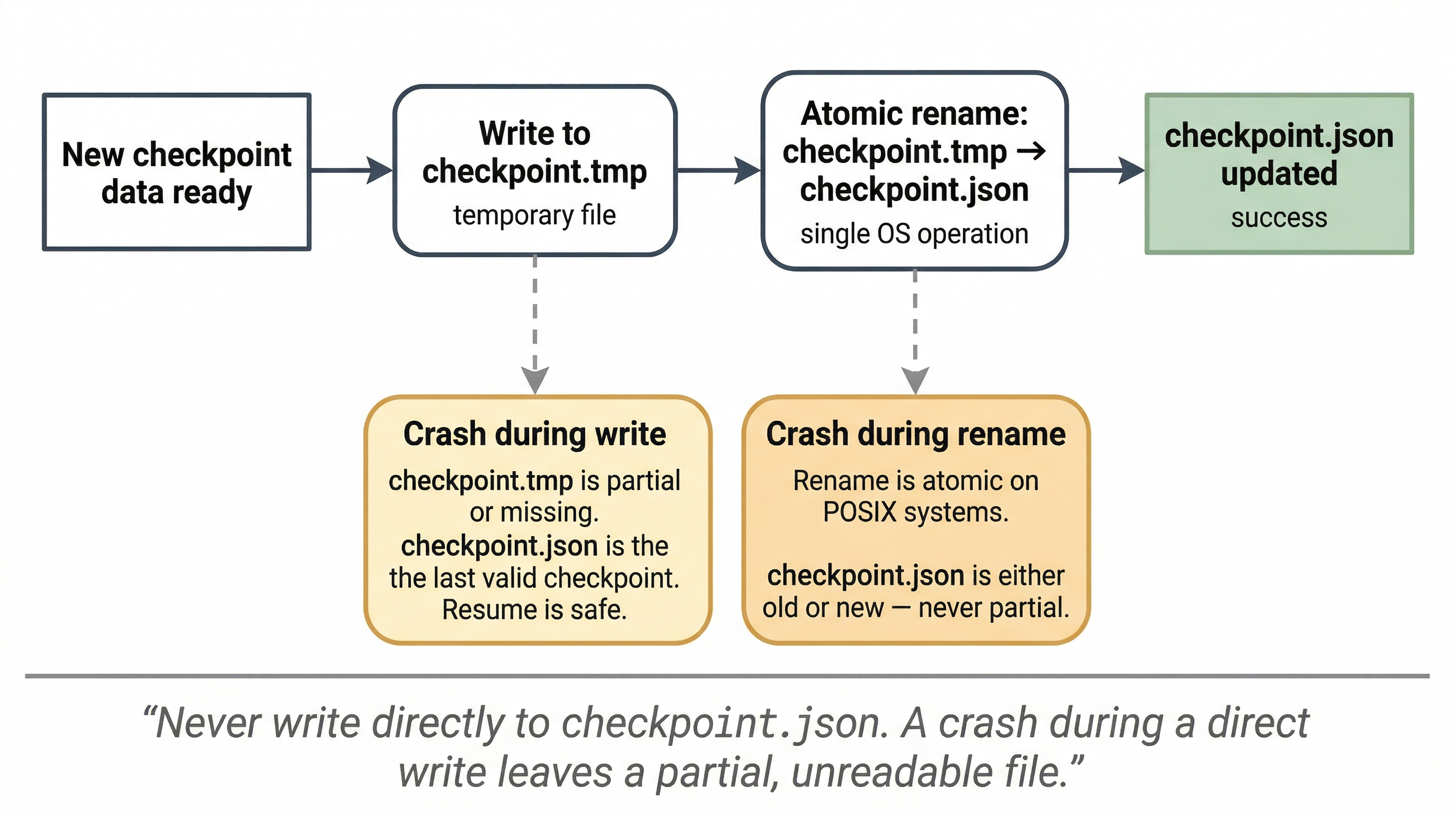
Figure 2:Transaction-safe checkpoint write pattern. Writing to a temp file and atomically renaming prevents checkpoint corruption on crash. A crash during the write phase leaves the old checkpoint intact. A crash during the rename (atomic on POSIX systems) leaves either the old or new checkpoint intact, never a partial file.
Resume logic. On startup, the pipeline checks for an existing checkpoint. If found: load it, determine what is already done, continue from where it stopped. If not found: start from the beginning. This should be automatic, not a manual decision.
When the checkpoint itself fails. If the checkpoint is corrupted or missing (disk failure, manual deletion, an incomplete write that the rename protection did not cover), the recovery path is the results file. Design your pipeline to write completed results independently of checkpoints: a separate, append-only results file that captures every successfully processed record. A corrupted checkpoint then costs you only the delta between what is in the results file and what was in the checkpoint. You resume from the last record in the results file, not from the beginning. The results file is your backstop when the checkpoint fails.
Recovery answers whether the pipeline resumes. It does not answer whether the resumed run produces equivalent output. A checkpoint restart changes the model’s context state: the prompt history, the sequence of prior outputs, even the random seed path may differ from an uninterrupted run. Chapter 8’s golden test set is the validation mechanism: run your recovered output against the same reference set you use for regression testing, and verify that the agreement metrics hold.
Parallel workers each maintain their own checkpoint. If one worker’s batch fails, only that worker restarts. The other workers’ completed work is preserved. This is the answer to Chapter 6’s reflection prompt: the whole pipeline does not restart, just the failed worker’s batch.
The Recursive Problem: Your Development Tools Are Also Stochastic¶
You are designing systems to manage LLM stochasticity using tools that are themselves stochastic. The engineering discipline required to build reliable LLM pipelines is the same discipline required to work with LLM coding assistants. The book’s thesis applies recursively.
When using LLMs to build LLM pipelines, the coding assistant ignores configuration files and hardcodes values from its training data. It reinvents debugged infrastructure from scratch, introducing bugs you already fixed. Its knowledge is frozen at its training cutoff, suggesting deprecated models, outdated API signatures, nonexistent model names. Each new session starts fresh; architectural decisions from previous sessions are lost.
Chen et al. (2026) evaluated AI coding agents on long-term codebase maintenance: 100 tasks, each spanning an average of 233 days and 71 consecutive commits in real Python repositories. 75% of the models tested (18 models from 8 providers) broke previously working features during maintenance. The agents produce quick fixes early but create mounting technical debt. The EvoScore metric, which weights later iterations more heavily, exposes this pattern: initial pass rates look acceptable, but accumulated regressions degrade the codebase over time.
The implication: your pipeline’s checkpoint and recovery architecture must survive not just runtime failures (API outages, rate limits) but also development-time regressions introduced by AI coding assistants. The config-driven architecture, progressive test infrastructure, and checkpoint/recovery patterns in this chapter all apply to the development process, not just the production pipeline. Your regression tests catch breakage whether it is caused by a provider change or by your coding assistant rewriting something it should not have touched.
Chapter 11 provides the full treatment of the development toolchain as part of the workflow architecture, including the specific protocol: specification before execution, verification before commit, regression testing after every AI-assisted change. This section states the problem and its immediate engineering consequences.
Thought Experiment¶
Your pipeline has been running in production for four months, processing 5,000 records weekly. You get a Monday morning alert: the weekend batch produced 5,000 results, zero errors, but spot-checking reveals that 30% of classifications have shifted categories compared to the same records processed three months ago. Your config file has not changed. Your code has not changed. Your data format has not changed.
What happened? Where do you start looking? What infrastructure from this chapter would have caught it earlier?
Config-driven architecture, progressive testing, and checkpoint and recovery make pipelines survivable. But survivable is not the same as valid. A pipeline can recover perfectly from every failure and still produce results that drift quietly over time, because the model changed, because the data changed, or because the accumulation of small shifts has moved your outputs away from where they started. Designing systems that detect this drift, that know when their own instrument has changed, requires both the evaluation infrastructure that Chapter 8 provides and the validity framework of Chapters 9 and 10.
- National Institute of Standards and Technology. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0) (Techreport NIST AI 100-1). NIST. https://csrc.nist.gov/pubs/ai/100/1/final
- Webb, B. (2026). AI-Assisted Federal Survey Harmonization: Cross-Survey Integration Analysis of 47 Census Bureau Demographic Surveys. Draft working paper. https://github.com/brockwebb/federal-survey-concept-mapper
- Chen, J., Xu, X., Wei, H., Chen, C., & Zhao, B. (2026). SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration. arXiv Preprint arXiv:2603.03823. https://arxiv.org/abs/2603.03823